Klasteryzacja w Python#
Wstęp#
Algorytmy klastrujące należą do grupy modeli uczenia maszynowego - konkretniej uczenia maszynowego bez nadzoru. Oznacza to, że zmienne nie dzielą się na zmienne objaśniające i zmienną celu. W tym kontekście nie mamy na czym “nadzorować” nauki naszego modelu. W przypadku tego rodzaju modeli naszym celem jest pogrupowanie danych w taki sposób, aby poszczególne skupienia, klastry jak najbardziej różniły się od siebie. Oczywiście podejście do grupowania różni się dla różnych zastosowań jednak ostatecznie chcemy aby poszczególne grupy obserwacji charakteryzowały się czymś innym.
Poniższy tutorial wprowadzi nas w świat metod klastrujących wychodząc od podstawowych modeli do coraz to trudniejszych. W trakcie nauki zobaczymy w jaki sposób działa każdy z algorytmów oraz na czym polegają główne różnice między nimi. Dzięki takiemu podejściu możliwym jest nabranie intuicji pozwalającej określić kiedy powinniśmy korzystać z jakiego modelu. Ponadto w końcowej fazie zostaną zaprezentowane podstawowe metody badania skuteczności algorytmów klastrujących.
Biblioteki#
# Manpulacja danych i operacje statystyczne
import numpy as np
# Przykladowe ramki danych
from sklearn.datasets import make_classification, make_blobs
# Wizualizacja danych
import seaborn as sns
from matplotlib import pyplot as plt
# Inne
import datetime as dt
Przygotowanie danych#
Do celów dydaktycznych przygotujemy 4 zbiory danych: \(X_1\), \(X_2\), \(X_3\) oraz \(X_4\). Każdy z tych zbiorów charakteryzuje się czym innym. Na ich podstawie postaram się pokazać różnice między algorytmami.
Losowe dane: \(X_1\)#
# Stworzenie losowego obiektu np.array
X_1, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
print(f'Typ obiektu: {type(X_1)}')
print(f'Typ danych: {X_1.dtype}')
print(f'Wymiar obiektu array: {X_1.shape}')
Typ obiektu: <class 'numpy.ndarray'>
Typ danych: float64
Wymiar obiektu array: (1000, 2)
# Wizualizacja
sns.relplot(x=X_1[:, 0], y=X_1[:, 1])
plt.title('Wykres rozrzutu zmiennej x i y')
plt.xlabel('x')
plt.ylabel('y');
Losowe dane: \(X_2\)#
n_samples = 1500
random_state = 170
X_2, _ = make_blobs(n_samples=n_samples, random_state=random_state)
print(f'Typ obiektu: {type(X_2)}')
print(f'Typ danych: {X_2.dtype}')
print(f'Wymiar obiektu array: {X_2.shape}')
Typ obiektu: <class 'numpy.ndarray'>
Typ danych: float64
Wymiar obiektu array: (1500, 2)
# Wizualizacja
sns.relplot(x=X_2[:, 0], y=X_2[:, 1])
plt.title('Wykres rozrzutu zmiennej x i y')
plt.xlabel('x')
plt.ylabel('y');
Losowe dane: \(X_3\)#
n_samples = 1000000
random_state = 170
X_3, _ = make_blobs(n_samples=n_samples, random_state=random_state)
print(f'Typ obiektu: {type(X_3)}')
print(f'Typ danych: {X_3.dtype}')
print(f'Wymiar obiektu array: {X_3.shape}')
Typ obiektu: <class 'numpy.ndarray'>
Typ danych: float64
Wymiar obiektu array: (1000000, 2)
# Wizualizacja
sns.relplot(x=X_3[:, 0], y=X_3[:, 1])
plt.title('Wykres rozrzutu zmiennej x i y')
plt.xlabel('x')
plt.ylabel('y');
Losowe dane: \(X_4\)#
# Set random state.
rs = np.random.seed(25)
def generate_circle_sample_data(r, n, sigma):
"""Generate circle data with random Gaussian noise."""
angles = np.random.uniform(low=0, high=2*np.pi, size=n)
x_epsilon = np.random.normal(loc=0.0, scale=sigma, size=n)
y_epsilon = np.random.normal(loc=0.0, scale=sigma, size=n)
x = r*np.cos(angles) + x_epsilon
y = r*np.sin(angles) + y_epsilon
return x, y
def generate_concentric_circles_data(param_list):
"""Generates many circle data with random Gaussian noise."""
x, y = [], []
for num, params in enumerate(param_lists):
x_, y_ = generate_circle_sample_data(*params)
x = np.concatenate([x, x_])
y = np.concatenate([y, y_])
X = np.array([x, y]).transpose()
return X
# Number of points per circle.
n = 1000
# Radius.
r_list =[2, 4, 6]
# Standar deviation (Gaussian noise).
sigma = 0.2
param_lists = [(r, n, sigma) for r in r_list]
X_4 = generate_concentric_circles_data(param_lists)
print(f'Typ obiektu: {type(X_4)}')
print(f'Typ danych: {X_4.dtype}')
print(f'Wymiar obiektu array: {X_4.shape}')
Typ obiektu: <class 'numpy.ndarray'>
Typ danych: float64
Wymiar obiektu array: (3000, 2)
# Wizualizacja
sns.relplot(x=X_4[:, 0], y=X_4[:, 1])
plt.title('Wykres rozrzutu zmiennej x i y')
plt.xlabel('x')
plt.ylabel('y');
Losowe dane: \(X_5\)#
# Number of points per circle.
n = 10000
# Radius.
r_list =[2, 4, 6]
# Standar deviation (Gaussian noise).
sigma = 0.2
param_lists = [(r, n, sigma) for r in r_list]
X_5 = generate_concentric_circles_data(param_lists)
X_5, _ = make_classification(n_samples=10000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=3, n_classes=1, random_state=4)
print(f'Typ obiektu: {type(X_5)}')
print(f'Typ danych: {X_5.dtype}')
print(f'Wymiar obiektu array: {X_5.shape}')
Typ obiektu: <class 'numpy.ndarray'>
Typ danych: float64
Wymiar obiektu array: (10000, 2)
# Wizualizacja
sns.relplot(x=X_5[:, 0], y=X_5[:, 1])
plt.title('Wykres rozrzutu zmiennej x i y')
plt.xlabel('x')
plt.ylabel('y');
Modele klastrujące#
W poniższym tutorialu zaprezentowanych zostanie kilka metod klastrowania, tj.:
K-Means
MiniBatch K-Means
Agglomerative Clustering
Spectral Clustering
DBSCAN
BIRCH
K-Means#
from sklearn.cluster import KMeans
Algorytm K-Means jest jednym z podstawowych modeli uczenia maszynowego wykorzystywanym do klastrowania obserwacji. Jego działanie polega na minimalizacji wariancji wewnątrz klastra. Algorytm wymaga podania liczby klastrów na ile chcemy poidzielić nasze obserwacje. Wybór liczby klastrów zależy od zależności statystycznych w naszych danych jak i również wymagań biznesowych.
Algorytm K-Means ma za zadanie podzielić \(N\) elementową próbę zmiennych losowych \(X_{j}\), gdzie \(j=1,2,...\) na \(K\) rozdzielnych klastrów \(C\), gdzie każdy z klastrów jest opisany przez średnią \(\mu_{k}\) próbek w klastrze. Wartości średnie \(\mu_{k}\) nazywane są centroidami lub środkami ciężkości klastra \(K\). Celem algorytmu jest wybór takich centroidów, które minimalizują wartość sumy kwadratów w ramach klastra:
gdzie \(N=\sum_{k=1}^{K} N_{k}\) oraz \(C(i)=k\) oznacza przynależność obserwacji \(i\) do klastra \(k\).
Czym jest K-Means ++#
Algorytm K-Means++ jest rozwinięciem algorytmu K-Means, które w głównej mierze polega na innej metodzie inicjalizacji centroidów. W klasycznej metodzie K-means centroidy w pierwszej iteracji dobierają się losowo - za wyjątkiem inicjalizacji ręcznej. W przypadku K-means++ inicjalizacja polega na wybraniu punktów (ogólnie) jak najbardziej oddalonych od siebie. Ostatecznie prowadzi to do lepszych wyników niż losowa inicjalizacja.
Przykład 1#
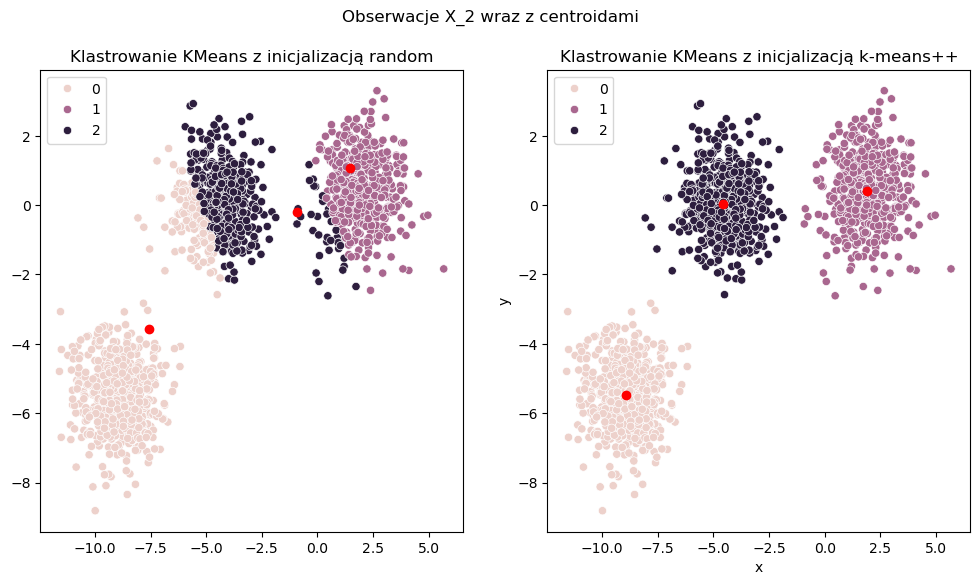
Aby lepiej zrozumieć zachowanie obu algorytmów warto spojrzeć na poniższą wizualizajcę. W tym przykładzie opieramy się na losowych obserwacjach X2, w których gołym okiem widać jak powinny rozłozyć się klastry dla tego zbioru. W pierwszej wizuzlizacji inijcalizujemy centroid przy pomocy estymatora KMeans biblioteki sklearn z inicjalizatorem random. W drugim przypadku inicjalizator random zastępujęmy algorytmem kmeans++. W obu przypadkach zakładamy jedną iterację algorytmu. Oznacza to, że w obu przypadkach początkowo wybrane centroidy będą tymi ostatecznymi.
# KMeans
np.random.seed(100)
algorithms = ['WARD', 'AVERAGE']
eval_times = []
shape_X = X_2.shape
## Inicjalizacja random
tic = dt.datetime.now()
model_random = KMeans(n_clusters=3, init='random', n_init=1, max_iter=1)
model_random.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_random = model_random.predict(X_2)
## Inicjalizacja k-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=3, init='k-means++', n_init=1, max_iter=1)
model_plusplus.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_2)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_random, ax=ax[0])
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_plusplus, ax=ax[1])
ax[0].plot(model_random.cluster_centers_[:, 0], model_random.cluster_centers_[:, 1], 'ro')
ax[0].set_title('Klastrowanie KMeans z inicjalizacją random')
ax[1].plot(model_plusplus.cluster_centers_[:, 0], model_plusplus.cluster_centers_[:, 1], 'ro')
ax[1].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_2 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
Data frame shape: (1500, 2)
[WARD] Duration: 0:00:00.901327
[AVERAGE] Duration: 0:00:00.020534
Tutaj widać przewagę inicjalizatora kmeans++, który już na początku jest w stanie dobrze podzialić nasz zbiór obserwacji na 3 niezależne klastry. W przypadku inicjalizacji random potrzebujemy większej liczby iteracji, aby znaleźć dobrą lokalizacje centroidów.
Zbieżność algorytmu KMeans zależy od liczby iteracji algorytmu. Zazwyczaj przy dużej liczbie iteracji powinniśmy znaleźć globalne minimum naszej funkcji celu. Niestety czasami istnieje ryzyko znalezienia się w lokalnym minimum.
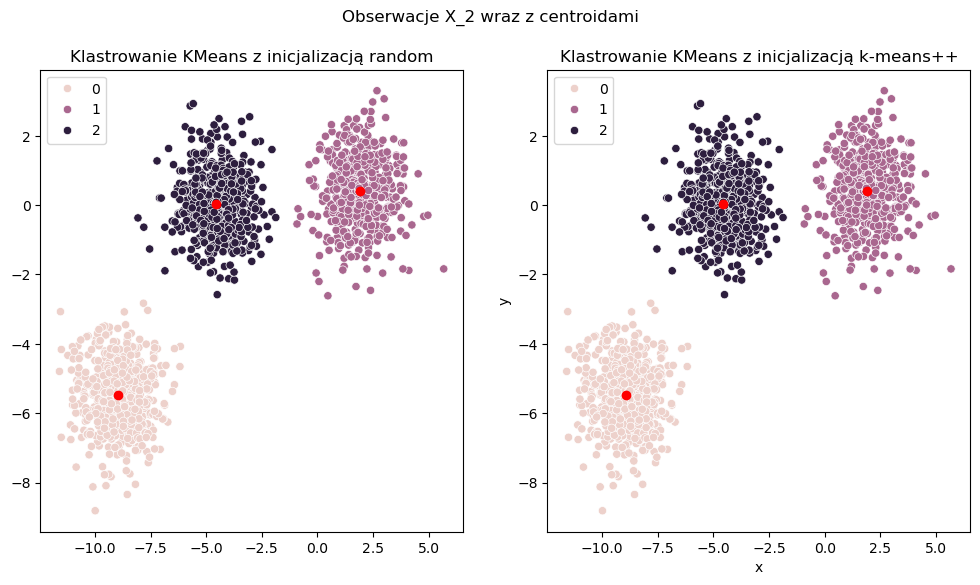
W tym prostym przypadku, w momencie gdy zwiększymy liczbę iteracji dla inicjalizacji random do 10, to algorytm osiąga przewidywane przez nas wyniki.
# KMeans
np.random.seed(100)
algorithms = ['KMEANS_RANDOM', 'KMEANS_++']
eval_times = []
shape_X = X_2.shape
## Inicjalizacja random
tic = dt.datetime.now()
model_random = KMeans(n_clusters=3, init='random', n_init=1, max_iter=10)
model_random.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_random = model_random.predict(X_2)
## Inicjalizacja k-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=3, init='k-means++', n_init=1, max_iter=1)
model_plusplus.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_2)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_random, ax=ax[0])
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_plusplus, ax=ax[1])
ax[0].plot(model_random.cluster_centers_[:, 0], model_random.cluster_centers_[:, 1], 'ro')
ax[0].set_title('Klastrowanie KMeans z inicjalizacją random')
ax[1].plot(model_plusplus.cluster_centers_[:, 0], model_plusplus.cluster_centers_[:, 1], 'ro')
ax[1].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_2 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
Data frame shape: (1500, 2)
[KMEANS_RANDOM] Duration: 0:00:00.015993
[KMEANS_++] Duration: 0:00:00.008008
Przykład 2#
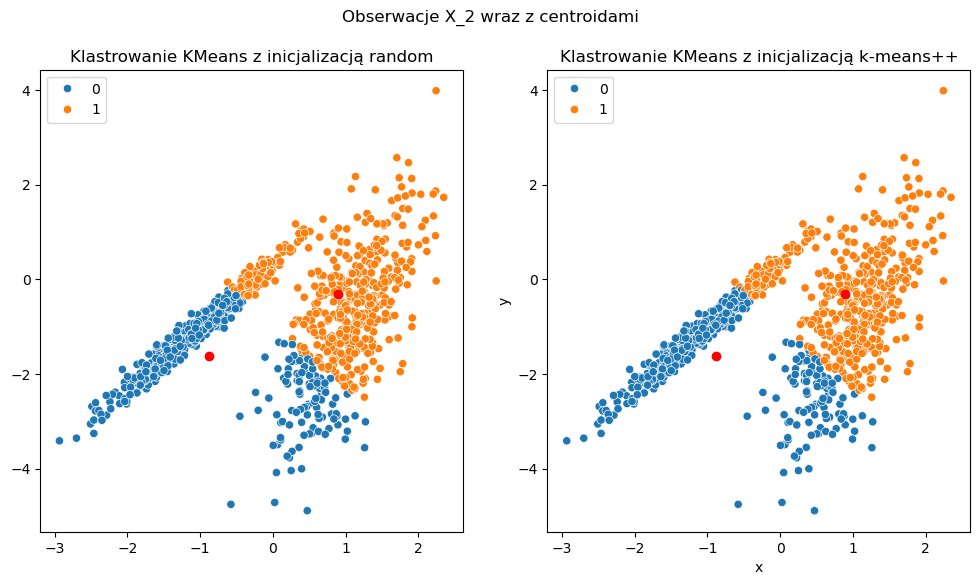
Poniższy przykład ilustruje zachowanie algorytmu KMeans w nie intuicyjny przez nas sposób. Oczekiwalibyśmy, aby algorytm klastrujący podzielił zbiór obserwacji na dwa klastry względem widocznych przez nas grup. Niestety tak się nie dzieje i jest to niezależne od liczby iteracji algorytu - poprostu KMeans nie est najlepszy w tego typu problemach.
# KMeans
np.random.seed(100)
algorithms = ['KMEANS_RANDOM', 'KMEANS_++']
eval_times = []
shape_X = X_2.shape
## Inicjalizacja random
tic = dt.datetime.now()
model_random = KMeans(n_clusters=2, init='random', n_init=10, max_iter=300)
model_random.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_random = model_random.predict(X_1)
## Inicjalizacja k-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=2, init='k-means++', n_init=10, max_iter=300)
model_plusplus.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_1)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_random, ax=ax[0])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_plusplus, ax=ax[1])
ax[0].plot(model_random.cluster_centers_[:, 0], model_random.cluster_centers_[:, 1], 'ro')
ax[0].set_title('Klastrowanie KMeans z inicjalizacją random')
ax[1].plot(model_plusplus.cluster_centers_[:, 0], model_plusplus.cluster_centers_[:, 1], 'ro')
ax[1].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_2 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
Data frame shape: (1500, 2)
[KMEANS_RANDOM] Duration: 0:00:00.145368
[KMEANS_++] Duration: 0:00:00.145300
Bibliografia [K-Means]#
https://scikit-learn.org/stable/modules/clustering.html#k-means
The Elements of. Statistical Learning: Data Mining, Inference, and Prediction. Second Edition. February 2009. Trevor Hastie · Robert Tibshirani
https://towardsdatascience.com/understanding-k-means-clustering-in-machine-learning-6a6e67336aa1
MiniBatch K-Means#
from sklearn.cluster import MiniBatchKMeans
Algorytm Minibatch KMeans jest jednym z wariantów algorytmu KMeans szczególnie użytecznym w przypadku bardzo dużych zbiorów danych - w przypadkach, gdy czas ewaluacji algorytmu liczy się bardziej niż jego dokładność. MiniBatch to podzbiór danych wejściowych, losowo próbkowany w każdej iteracji podczas treningu modelu. W efekcie podział zbioru treningowego na mini-batche redukuję czas kalkulacji potrzebny do osiągnięcia zbieżności algorytmu. Ostatecznie algorytm oparty o mini-batche w ogólności osiąga tylko nieco gorsze wyniki niż klasyczna metoda Kmeans.
Przykład#
Zastosowanie algorytmu MiniBatch K-Means w przypadku jasno widocznych klastrów, jednak gdy obserwacji mamy więcej działa tak samo daję takie same wyniki jak algorytm Kmeans. Jednak w tym przypadku zależy nam na sprawdzeniu czasu przetwarzania - to tutaj powinna być widoczna różnica. Tak też się dzieje. Widoczny czas przetwarzania jasno wskazuje na przewagę algorytmu MiniBatch K-Means w przypadku dużych próbek. Czas przetwarzania w tym przypadku jest kilka razy szybszy przy zachowaniu niemal takiego samego podziału na klastry.
np.random.seed(100)
algorithms = ['KMEANS_++', 'MINIBATCH_KMEANS']
eval_times = []
shape_X = X_3.shape
# KMeans
tic = dt.datetime.now()
model_random = KMeans(n_clusters=3, init='k-means++', n_init=20, max_iter=1000)
model_random.fit(X_3)
eval_times.append(dt.datetime.now() - tic)
y_cluster_random = model_random.predict(X_3)
# Minibatch K-means
tic = dt.datetime.now()
model_minibatch = MiniBatchKMeans(n_clusters=3, init='k-means++', n_init=20, max_iter=1000, batch_size=100)
model_minibatch.fit(X_3)
eval_times.append(dt.datetime.now() - tic)
y_cluster_minibatch = model_minibatch.predict(X_3)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_3[:, 0], y=X_3[:, 1], hue=y_cluster_random, ax=ax[0])
sns.scatterplot(x=X_3[:, 0], y=X_3[:, 1], hue=y_cluster_minibatch, ax=ax[1])
ax[0].plot(model_random.cluster_centers_[:, 0], model_random.cluster_centers_[:, 1], 'ro')
ax[0].set_title('Klastrowanie MiniBatch KMeans')
ax[1].plot(model_minibatch.cluster_centers_[:, 0], model_minibatch.cluster_centers_[:, 1], 'ro')
ax[1].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_3 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1955: UserWarning: MiniBatchKMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can prevent it by setting batch_size >= 3584 or by setting the environment variable OMP_NUM_THREADS=1
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\IPython\core\pylabtools.py:170: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
fig.canvas.print_figure(bytes_io, **kw)
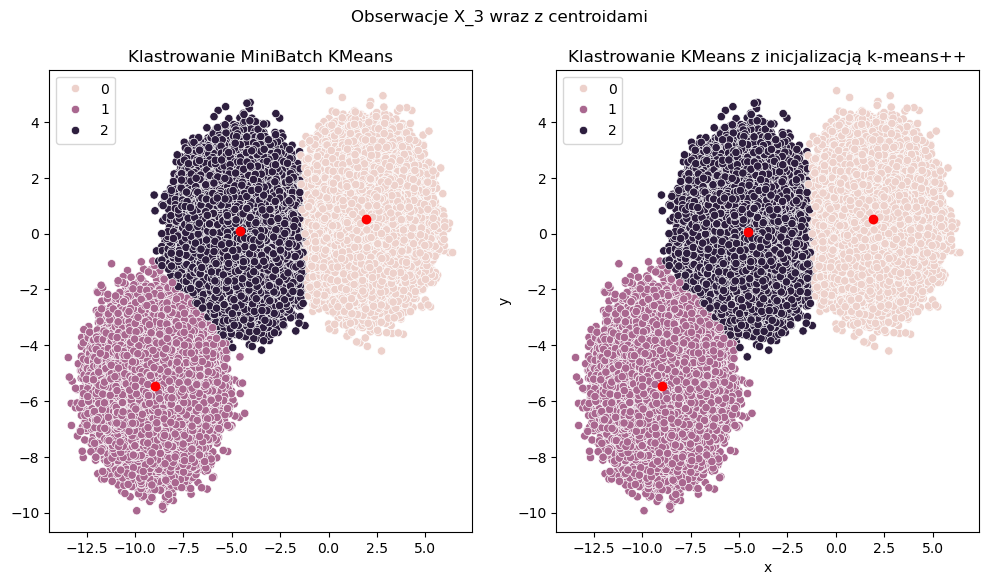
Data frame shape: (1000000, 2)
[KMEANS_++] Duration: 0:00:06.672291
[MINIBATCH_KMEANS] Duration: 0:00:00.393778
Korzystając z kodu dostępnego przy powyższych wizualizacjach znajdź współrzędne centroidów dla algorytmu KMeans oraz MiniBatchKMeans. Czy w tym przypadku jest jakaś różnica ? Policz odległość Euklidesową między nimi.
Podpowiedź: Najpierw znajdź punkty, które są najbliżej siebie. Może się zdarzyć, że oznaczenie klastrów 0, 1, 2 będzie różne dla różnych algorytmów.
Bibliografia [Minibatch K-Means]#
Agglomerative Clustering#
from sklearn.cluster import AgglomerativeClustering
Klastrowanie hierarchiczne polega na budowaniu zagnieżdżonych klastrów poprzez ich kolejne scalanie lub dzielenie. Hierarchia klastrów jest reprezentowana jako drzewo (lub dendrogram). Korzeń drzewa jest unikalnym skupiskiem, które gromadzi wszystkie próbki, a liście są skupiskami z tylko jedną próbką. Obiekt AgglomerativeClustering wykonuje hierarchiczne grupowanie przy użyciu podejścia oddolnego: każda obserwacja rozpoczyna się we własnym klastrze, a klastry są sukcesywnie łączone ze sobą. Kryteria powiązania linkage określają metrykę używaną w strategii łączenia:
Ward - minimalizuje sumę kwadratów różnic we wszystkich klastrach. Jest to podejście minimalizujące wariancje i w tym sensie jest podobne do funkcji celu k-średnich, ale rozwiązywane za pomocą aglomeracyjnego podejścia hierarchicznego.
Maximum linkage/Complete linkage - minimalizuje maksymalną odległość między obserwacjami par klastrów.
Average linkage - minimalizuje średnią odległości między wszystkimi obserwacjami par klastrów.
Single linkage - minimalizuje odległość pomiędzy najbliższymi obserwacjami par klastrów.
Przykład 1#
Metody aglomeracyjne w przypadku klastrów o jasno widocznym środku ciężkości klastra radzą sobie bardzo dobrze. Obie metody Ward oraz Average bardzo dobrze dzielą obserwacje na klastry. Podział jest taki sam jak w przypadku algorytmów z rodziny KMeans.
np.random.seed(100)
algorithms = ['WARD', 'AVERAGE']
eval_times = []
shape_X = X_2.shape
# Algorytm Ward
tic = dt.datetime.now()
model_ward = AgglomerativeClustering(n_clusters=3, linkage='ward',) # affinity='euclidean'
model_ward.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_ward = model_ward.labels_
# Algorytm Average
tic = dt.datetime.now()
model_avg = AgglomerativeClustering(n_clusters=3, linkage='average',) # affinity='euclidean'
model_avg.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_avg = model_avg.labels_
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(18, 6))
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_ward, ax=ax[0])
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_avg, ax=ax[1])
ax[0].set_title('Klastrowanie WARD linkage')
ax[1].set_title('Klastrowanie Average linkage')
plt.suptitle('Obserwacje X_1')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
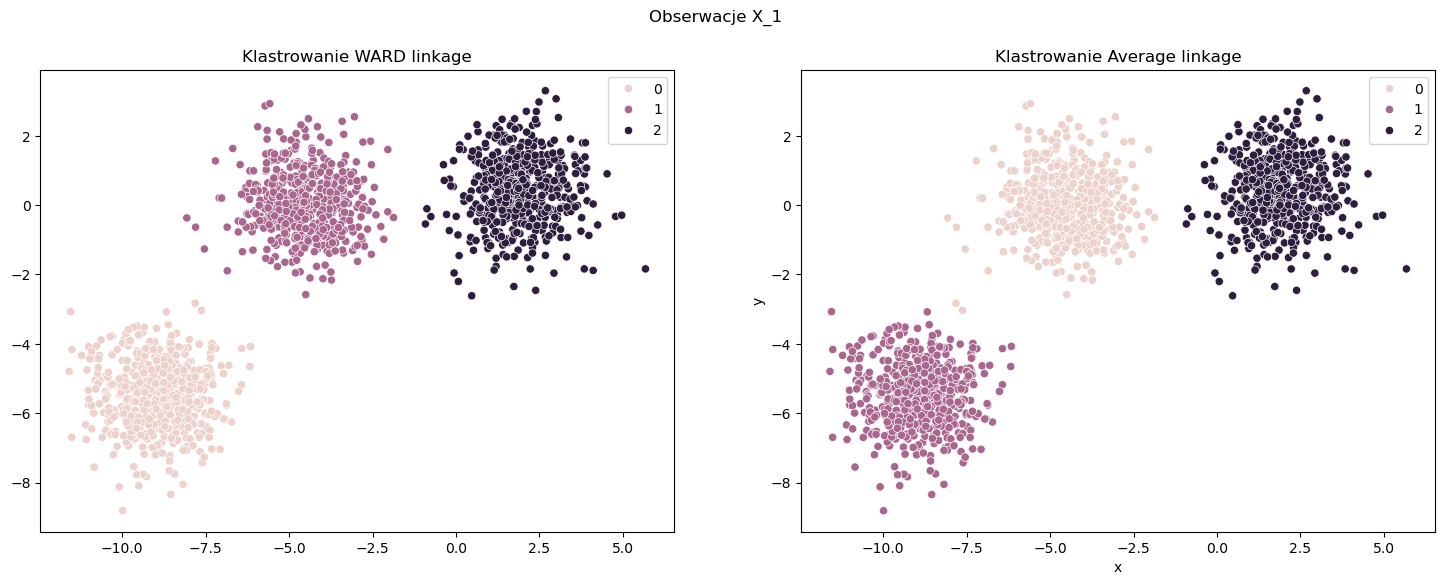
Data frame shape: (1500, 2)
[WARD] Duration: 0:00:00.075152
[AVERAGE] Duration: 0:00:00.083469
Przykład 2#
Drugi przykład jest nieco trudniejszy. Klastry są widoczne ale są różnych kształtów. W tym przypadku oba algorytmy sobie nie radzą. Metoda Ward dzieli klastry podobnie jak algorytm KMeans. W przypadku metody opartej o powiązanie Average dostajemy dwa klastry z czego jeden z nich składa się z jednej obserwacji - raczej nie tego oczekujemy po algorytmie klastrującym.
np.random.seed(100)
algorithms = ['WARD', 'AVERAGE']
eval_times = []
shape_X = X_1.shape
# Algorytm Ward
tic = dt.datetime.now()
model_ward = AgglomerativeClustering(n_clusters=2, linkage='ward', ) # affinity='euclidean'
model_ward.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_ward = model_ward.labels_
# Algorytm Average
tic = dt.datetime.now()
model_avg = AgglomerativeClustering(n_clusters=2, linkage='average', ) # affinity='euclidean'
model_avg.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_avg = model_avg.labels_
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(18, 6))
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_ward, ax=ax[0])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_avg, ax=ax[1])
ax[0].set_title('Klastrowanie WARD linkage')
ax[1].set_title('Klastrowanie Average linkage')
plt.suptitle('Obserwacje X_1')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
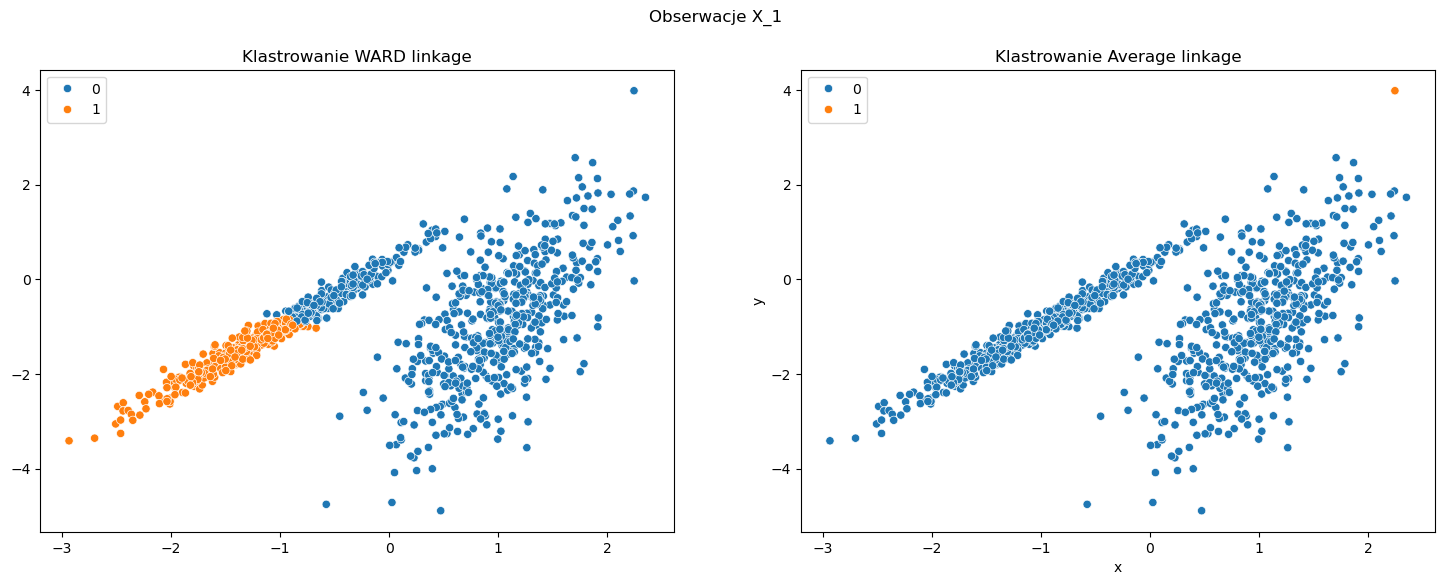
Data frame shape: (1000, 2)
[WARD] Duration: 0:00:00.050071
[AVERAGE] Duration: 0:00:00.060946
Spróbuj analogicznie jak powyżej zastosować algorytmy Single Linkage oraz Maximum Linkage.
Bibliografia [Agglomerative Clustering]#
Spectral Clustering#
from sklearn.cluster import SpectralClustering
W praktyce Spectral Clustering jest bardzo przydatne, gdy struktura poszczególnych klastrów jest wysoce niewypukła lub bardziej ogólnie, gdy miara środka i rozproszenia klastra nie jest odpowiednim opisem całego klastra, na przykład gdy klastry są zagnieżdżonymi okręgami na płaszczyźnie 2D. Cała teoria związana z klastrowaniem spektralnym wywodzi się z teorii grafów oraz algebry liniowej. Algorytm składa się na wejściu danych w postaci macierzy podobieństwa adjacency matrix, a następnie wyznacza się macierz Laplace’a. Kolejnym etapem jest wyliczenie wektorów i wartosci własnych macierzy Laplace’a. Ostatecznie na wyznaczonych wektorach własnych uruchamiany algorytm k-means.
Aby wyliczyć macierz adjacency matrix możemy wykorzystać metody: skorzystać z algorytmu k nearest neighbors lub skorzystać z kalkulacji przy pomocy jądra rbf. W pierwszym przypadku do wyliczenia maceirz wykorzystujemy teorię grafów oraz algorytm k nearest neighbor znajdujący k najbliższych sąsiadów. W drugim przypadku wykorzystujemy jądro RBF, które (Radial basis function) na dwóch próbkach \(x_{1}\) i \(x_{2}\), reprezentowanych jako wektory cech w pewnej przestrzeni wejściowej, jest zdefiniowane jako:
gdzie parameter \(\gamma\) jest parametrem modelu. Czasami możemy się spotkać z zapisem gdzie \(\gamma = \frac{1}{2\sigma^{2}}\). Wynika to z tego, że jądro RBF jest pewnym “uogólnieniem” jądra Gaussowskiego. W dużym uproszczeniu oznacza to, że przy wywołaniu metody fit liczymy macierz adjacency matrix przy pomocy jądra RBF. A następnie dokonywana są kolejne kalkulacje tj. kalkulacja macierzy Laplace’a oraz wyznaczenie wektorów i wartości własnych.
Przykład#
W poniższym przykładzie dużo lepszym wyborem jest algorytm SpectralClustering wraz z metodą wyznaczenia macierzy podobieństwa affinity ustawioną jako rbf. Przy dobrze dobranych hiperparametrach jesteśmy w stanie skutecznie odseparować od siebie obie grupy obserwacji. W moim odczuciu dobranie lepszych wartości parametrów dla metody knn jest trudniejsze. Ponadto wydaje się, że algorytm oparty o rbf działa nieco szybciej.
np.random.seed(100)
algorithms = ['SPECTRAL_KNN', 'SPECTRAL_RBF', 'KMEANS']
eval_times = []
shape_X = X_1.shape
# Spectral Clustering (KNN)
tic = dt.datetime.now()
model_sc = SpectralClustering(n_clusters=2, n_neighbors=10, affinity='nearest_neighbors', assign_labels='kmeans')
model_sc.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_spectral_knn = model_sc.labels_
# Spectral Clustering (RBF)
tic = dt.datetime.now()
model_sc = SpectralClustering(n_clusters=2, gamma=10.0, affinity='rbf', assign_labels='kmeans')
model_sc.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_spectral_rbf = model_sc.labels_
# K-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=2, init='k-means++')
model_plusplus.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_1)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_spectral_knn, ax=ax[0])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_spectral_rbf, ax=ax[1])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_plusplus, ax=ax[2])
ax[0].set_title('Klastrowanie Spectral Clustering (KNN)')
ax[1].set_title('Klastrowanie Spectral Clustering (RBF)')
ax[2].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_1 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
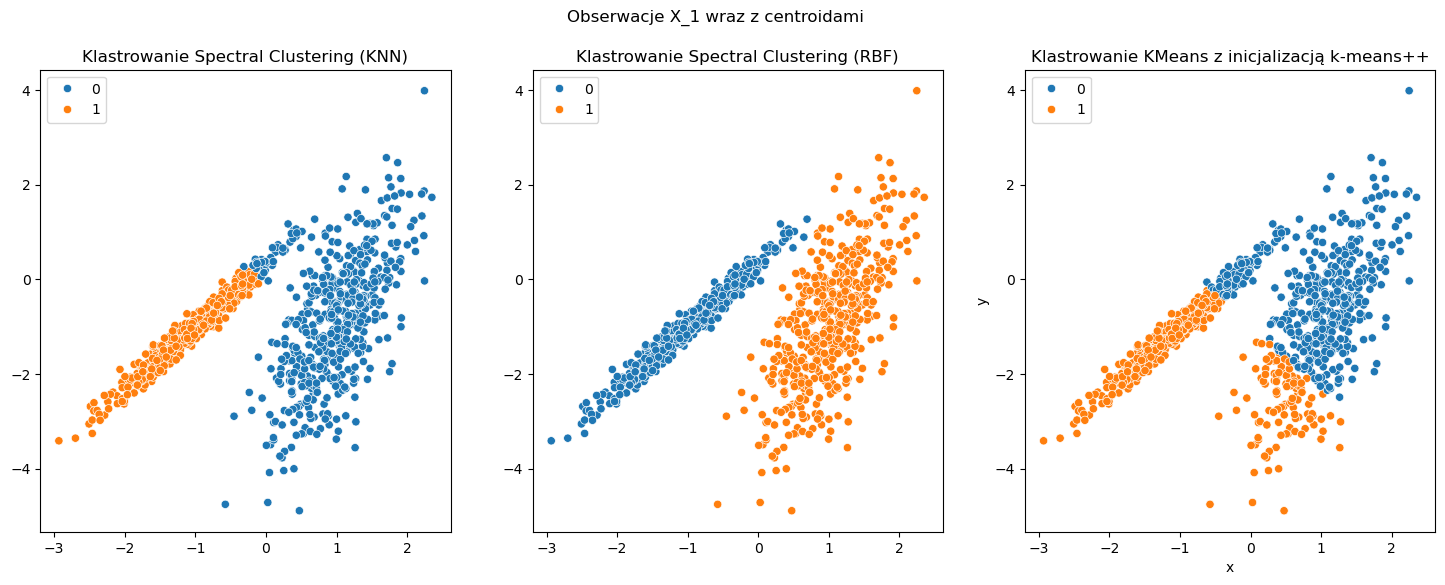
Data frame shape: (1000, 2)
[SPECTRAL_KNN] Duration: 0:00:00.645858
[SPECTRAL_RBF] Duration: 0:00:04.004907
[KMEANS] Duration: 0:00:00.031682
Sprawdź co się stanie gdy zmienisz wartość parametru gamma.
Bibliografia [Spectral Clustering]#
DBSCAN#
from sklearn.cluster import DBSCAN
Algorytm DBSCAN w dużym uproszczeniu polega na interpretacji klastrów jako pół o wysokiej gęstości odseparowanych polami o niskiej gęstości. To powoduję, że klastry znaleznione przy pomocy alorytmu DBSCAN mogą mieć dowolny kształt w stosunku do klastrów powstałych przy pomocy algorytmu KMeans, który zakłada wypukłość klastrów. Główną składową algorytmu jest pojęcie próbki podstawowej, która jest próbką znajdującą się w obszarze wysokiej gęstości. Wtedy klaster jest zbiorem próbek podstawowych, dla których każda jest blisko kolejnej próbki (odległość liczona za pomocą przyjętej metryki odległości) oraz zbioru próbek niepodstawowych, które są blisko próbki podstawowej, ale nie są próbką podstawową. Algorytm opiera się na dwóch podstawowych parametrach: min_samples oraz eps, które formalnie definiują co użytkownik ma na myśli mówiąc o gęstości. Wysoka wartość min_samples oraz niska wartość eps oznacza potrzebę uzyskania wyższej gęstości obserwacji potrzebną do uformowania się klastra. Dokładniej, definujemy próbkę podstawową jako podzbiór obserwacji dla którego istnieje min_samples innych podzbiorów w odległości eps, które są “sąsiadami” próbki podstawowej. Oznacza to, że próbka podstawowa znajduje się w gęstym obszarze przestrzeni wektorowej.
Przykład 1#
Pierwszy przykład obejmuje klastrowanie zbioru \(X_1\). Poniżej porówanjmy zachowanie trzech algorytmów: DBSCAN, Spectral Clustering oraz KMeans. Warto zwrócić uwagę na jedną rzecz w przypadku algorytmu DBSCAN. Przy definiowaniu parametrów modelu nie zajdziemy parametru n_clusters tak jak w przypadku poprzednich. Jest to bardzo duży atut tego aglorytmu, ponieważ on sam dzieli nasz zbiór na odpowiednią liczbę klastrów w zależności jak zdefiniujemy gęstość za pomocą parametrów min_samples oraz eps.
Przy zadanych parametrach wydaję się, że algorytm Spectral Clustering działa najlepiej. Jednak jak przyjrzymy się bliżej to może się wydawać, że algorytm DBSCAN dzieli obserwacje na 3 klastry. Nic bardziej mylnego. Labelka “-1” oznacza, że daną obsewację nie udało się zaliczyć do żadnego klastra - przynajmniej w przypadku tak określonych parametrów min_sample oraz eps. Zatem obserwacje z labelką “-1” można określić jako anomalie w danym zbiorze obserwacji. Właśnie wykrywanie anomalii jest kolejnym zastosowaniem algorytmu DBSCAN oprócz klastrowania. W powyższym przykładzie zapewne uda się podzielić zbiór przy pomocy DBSCAN jeszcze lepiej (zmieniając parametry), ponieważ wydaję się że niektóre z obserwacji mogą jednak nie być anomaliami.
np.random.seed(100)
algorithms = ['DBSCAN', 'SPECTRAL', 'KMEANS++']
eval_times = []
shape_X = X_1.shape
# Algorytm DBSCAN
tic = dt.datetime.now()
model_dbscan = DBSCAN(eps=0.3, min_samples=10, metric='euclidean')
model_dbscan.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_dbscan = model_dbscan.labels_
# Spectral clustering
tic = dt.datetime.now()
model_sc = SpectralClustering(n_clusters=2, gamma=10.0)
model_sc.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_sc = model_sc.labels_
# K-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=2, init='k-means++')
model_plusplus.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_1)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_dbscan, ax=ax[0])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_sc, ax=ax[1])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_plusplus, ax=ax[2])
ax[0].set_title('Klastrowanie DBSCAN')
ax[1].set_title('Klastrowanie Spectral Clustering')
ax[2].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_1 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
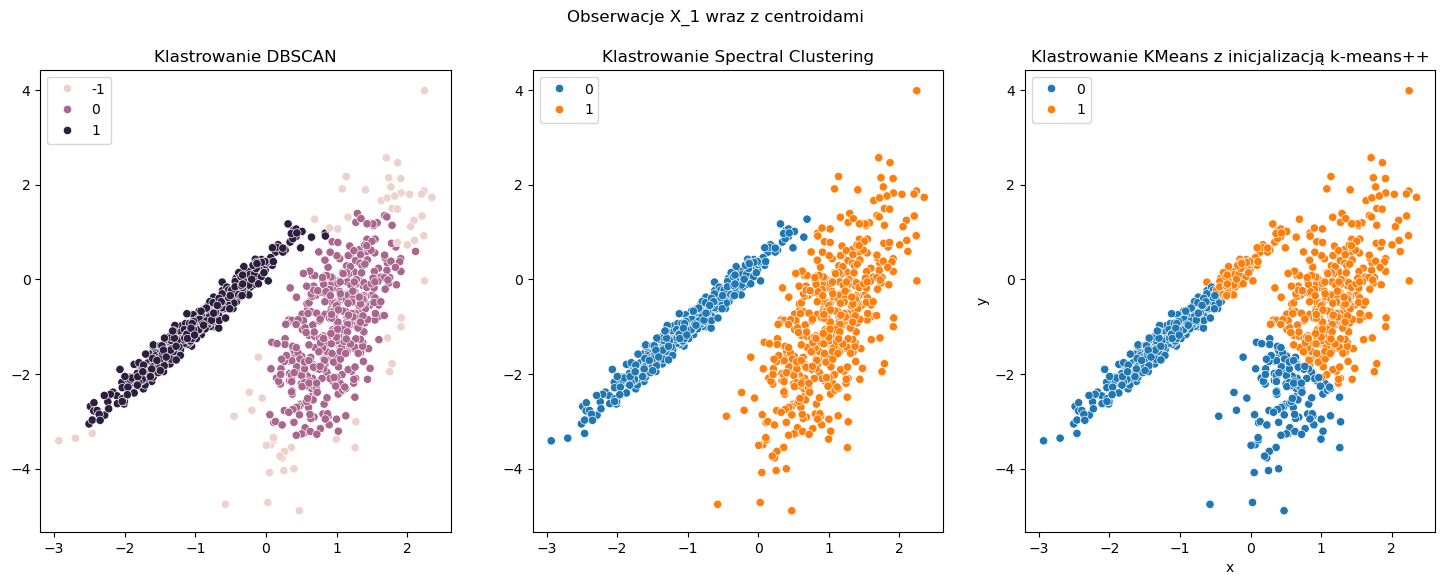
Data frame shape: (1000, 2)
[DBSCAN] Duration: 0:00:00.034099
[SPECTRAL] Duration: 0:00:02.910082
[KMEANS++] Duration: 0:00:00.017830
Spróbuj nieco zmienić hiperparametry min_samples oraz eps. Czy uda ci się lepiej podzielić obserwacje na klastry ?
Przykład 2#
Tym razem na warsztat weźmy zbiór danych \(X_4\), który składa się z trzech okręgów o różnej średnicy. Zobaczmy jak w tym przypadku zadziała algorytm DBSCAN na tle innych.
Jak widać z powyższymi parametrami model DBSCAN znajduję klastry w taki sam sposób jak model Spectral Clustering. Jednakże bardzo duża różnica tkwi w czasie przeliczeń. W przypadku DBSCAN klastrowanie następuje ponad 1000 razy szybciej - przynajmniej w tym konkretnym przypadku. Wynika to ze złożoności obliczeń w algorytmie Spectral Clustering. Jeśli chodzi o KMeans to podobnie jak było to w Przykład 1 klastry są dobierane zgodnie z założeniem wypukłości klastrów, co w tym przypadku nie jest oczekiwane.
np.random.seed(100)
algorithms = ['DBSCAN', 'SPECTRAL', 'KMEANS++']
eval_times = []
shape_X = X_4.shape
# Algorytm DBSCAN
np.random.seed(100)
tic = dt.datetime.now()
model_dbscan = DBSCAN(eps=0.5, min_samples=5, metric='euclidean')
model_dbscan.fit(X_4)
eval_times.append(dt.datetime.now() - tic)
y_cluster_dbscan = model_dbscan.labels_
# Algorytm Spectral clustering
tic = dt.datetime.now()
model_sc = SpectralClustering(n_clusters=3, gamma=10.0)
model_sc.fit(X_4)
eval_times.append(dt.datetime.now() - tic)
y_cluster_sc = model_sc.labels_
# Algorytm K-means++
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=3, init='k-means++')
model_plusplus.fit(X_4)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_4)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.scatterplot(x=X_4[:, 0], y=X_4[:, 1], hue=y_cluster_dbscan, ax=ax[0])
sns.scatterplot(x=X_4[:, 0], y=X_4[:, 1], hue=y_cluster_sc, ax=ax[1])
sns.scatterplot(x=X_4[:, 0], y=X_4[:, 1], hue=y_cluster_plusplus, ax=ax[2])
ax[0].set_title('Klastrowanie DBSCAN')
ax[1].set_title('Klastrowanie Spectral Clustering')
ax[2].set_title('Klastrowanie KMeans z inicjalizacją k-means++')
plt.suptitle('Obserwacje X_4 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=12.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=12.
warnings.warn(
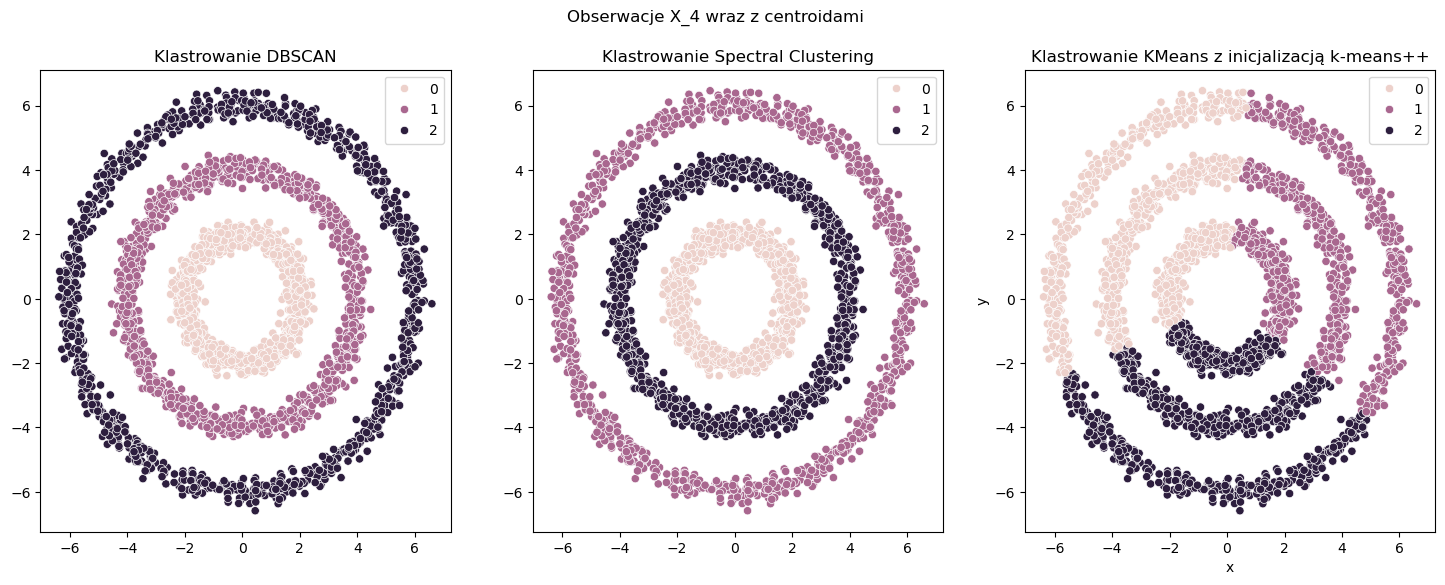
Data frame shape: (3000, 2)
[DBSCAN] Duration: 0:00:00.066052
[SPECTRAL] Duration: 0:01:00.810165
[KMEANS++] Duration: 0:00:00.031668
Bibliografia [DBSCAN]#
BIRCH#
from sklearn.cluster import Birch
Algorytm Balanced Iterative Reducing and Clustering using Hierarchies w skrócie BIRCH buduje drzewo o nazwie Clustering Feature Tree (CFT) dla podanych danych, które są kompresowane stratnie do zestawu węzłów Clustering Feature Nodes (Nodes CF). Węzły CF mają pewną liczbę podklastrów zwanych Clustering Feature Subclasters (CFS). Podklastry CF przechowują informacje niezbędne do grupowania, co zapobiega konieczności przechowywania wszystkich danych wejściowych w pamięci. Informacje te obejmują:
Number of Samples - liczbę próbek w podgrupie,
Linear Sum - sumę liniową, która jest n-wymiarowem wektorm przechowującym sumę wszystkich próbek,
Squared Sum - suma kwadratów normy L2 dla wszystkich próbek,
Centroids - centroidy równe Linear Sum / Number of Samples,
Norma kwadratowa centroidów.
W dużym uproszczeniu algorytm BIRCH zajmuje się dużymi zestawami danych, najpierw generując bardziej zwarte podsumowanie, które zachowuje jak najwięcej informacji o rozkładzie, a następnie grupując podsumowanie danych zamiast oryginalnego zestawu obserwacji. Więcej informacji znajdziecie pod linkami w bibliografii.
Przykład 1#
np.random.seed(100)
algorithms = ['BIRCH', 'MINIBATCH_KMEANS']
eval_times = []
shape_X = X_3.shape
# BIRCH
tic = dt.datetime.now()
model_brc = Birch(n_clusters=3, threshold=0.5, branching_factor=50)
model_brc.fit(X_3)
eval_times.append(dt.datetime.now() - tic)
y_cluster_birch = model_brc.labels_
# Minibatch K-means
tic = dt.datetime.now()
model_minibatch = MiniBatchKMeans(n_clusters=3, init='k-means++', n_init=20, max_iter=1000, batch_size=100)
model_minibatch.fit(X_3)
eval_times.append(dt.datetime.now() - tic)
y_cluster_minibatch = model_minibatch.predict(X_3)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_3[:, 0], y=X_3[:, 1], hue=y_cluster_birch, ax=ax[0])
sns.scatterplot(x=X_3[:, 0], y=X_3[:, 1], hue=y_cluster_minibatch, ax=ax[1])
ax[0].set_title('Klastrowanie BIRCH')
ax[1].set_title('Klastrowanie MiniBatch KMeans')
plt.suptitle('Obserwacje X_3')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1955: UserWarning: MiniBatchKMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can prevent it by setting batch_size >= 3584 or by setting the environment variable OMP_NUM_THREADS=1
warnings.warn(
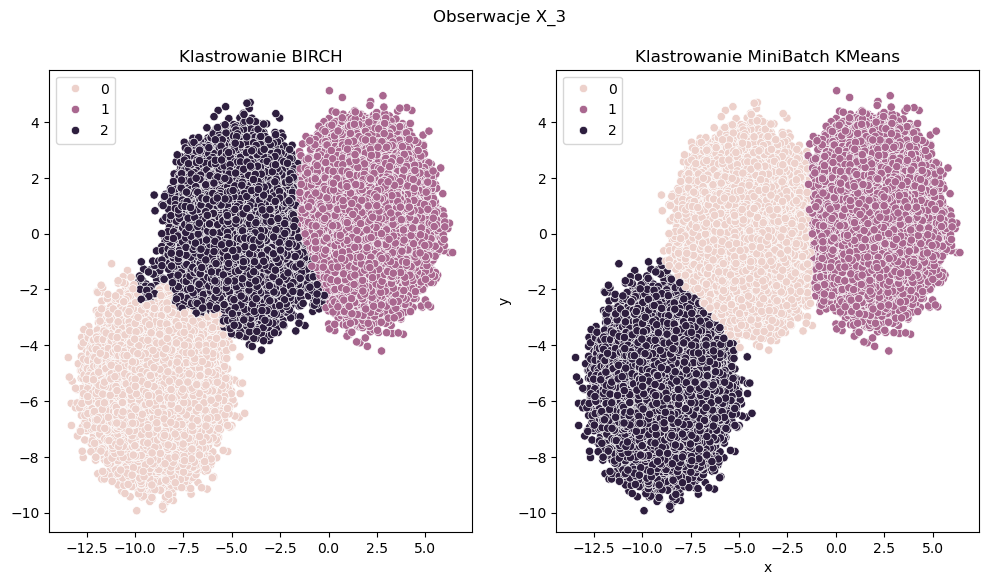
Data frame shape: (1000000, 2)
[BIRCH] Duration: 0:00:14.610723
[MINIBATCH_KMEANS] Duration: 0:00:25.972900
Przykład 2#
np.random.seed(100)
algorithms = ['BIRCH', 'MINIBATCH_KMEANS']
eval_times = []
shape_X = X_5.shape
# BIRCH
tic = dt.datetime.now()
model_brc = Birch(n_clusters=3, threshold=0.5, branching_factor=50)
model_brc.fit(X_5)
eval_times.append(dt.datetime.now() - tic)
y_cluster_birch = model_brc.labels_
# Minibatch K-means
tic = dt.datetime.now()
model_minibatch = MiniBatchKMeans(n_clusters=3, init='k-means++', n_init=20, max_iter=1000, batch_size=100)
model_minibatch.fit(X_5)
eval_times.append(dt.datetime.now() - tic)
y_cluster_minibatch = model_minibatch.predict(X_5)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))
sns.scatterplot(x=X_5[:, 0], y=X_5[:, 1], hue=y_cluster_birch, ax=ax[0])
sns.scatterplot(x=X_5[:, 0], y=X_5[:, 1], hue=y_cluster_minibatch, ax=ax[1])
ax[0].set_title('Klastrowanie BIRCH')
ax[1].set_title('Klastrowanie MiniBatch KMeans')
plt.suptitle('Obserwacje X_5')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Cza kalkulacji
print(f'Data frame shape: {shape_X}')
for algorithm, etime in zip(algorithms, eval_times):
print(f'[{algorithm}] Duration: {etime}')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1955: UserWarning: MiniBatchKMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can prevent it by setting batch_size >= 3584 or by setting the environment variable OMP_NUM_THREADS=1
warnings.warn(
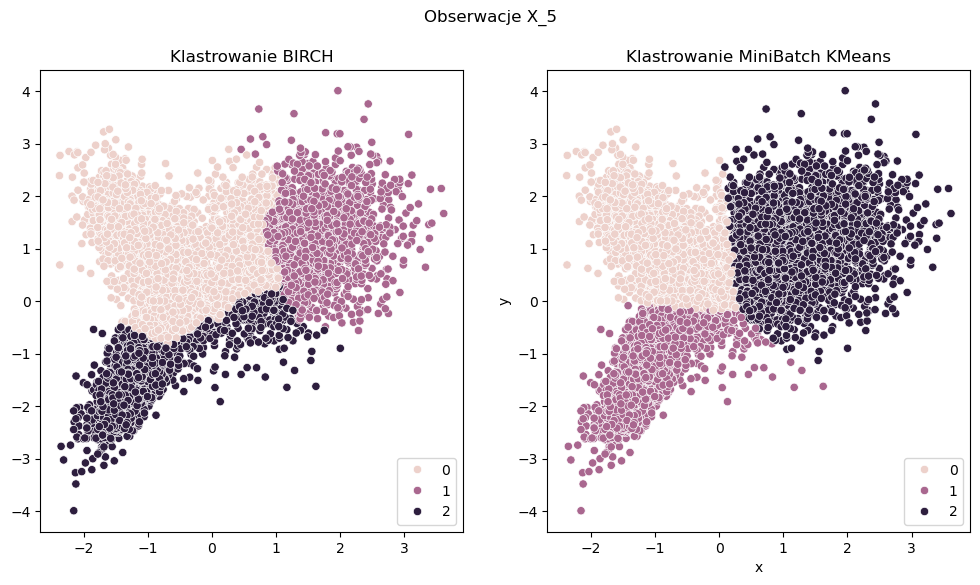
Data frame shape: (10000, 2)
[BIRCH] Duration: 0:00:00.078239
[MINIBATCH_KMEANS] Duration: 0:00:00.834230
Bibliografia [BIRCH]#
Analiza skuteczności#
Badanie skuteczności algorytmów klastrujących nie jest łatwe. W zależności od problemu biznesowego oczekujemy zupełnie innych wyników. Dodatkowo w przypadku danych wielowymiarowych, gdzie wykorzystujemy do klastrowania więcej niż dwie, trzy zmienne pojawiają się dodatkowo problemy z wizualizacją wyników. W tym przypadku mogą się przydać algorytmy z rodziny redukcji wymiarowości tj. PCA, ICA czy TSNE. Nadal jednak potrzebujemy odpowiedzieć sobie na pytanie czy dany podział na klastry jest prawidłowy ? W końcu nie będziemy dokonywać decyzji biznesowych wyłącznie na podstawie wizualizacji wyników - do tego potrzebujemy odpowiednich metryk. Dodatkowo w przypadku automatyzacji naszego procesu nie będzie czasu na to, aby przy każdym przeliczeniu sprawdzać wizualne wyniki, ale będziemy chcieli podejmować decyzje na podstawie wybranej, bądź wybranych metryk aby ostatecznie nasz proces był w pełni zautomatyzowany.
W poniższej części zostanie wprowadzonych kilka podstawowych miar, które mogą pomóc nam w zadaniu analizy skuteczności klastrowania.
Silhouette Coefficient#
from sklearn.metrics import silhouette_score
Jedną z najpopularniejszych metod do oceny jakości klastrowania jest metryka Silhouette Coefficient. Jej wysoką wartość interpretujemy jako bardzo dobrze wykonane klastrowanie. Metryka zdefiniowana jest dla każdej obserwacji z osobna w następujący sposób:
gdzie:
a: średnia odległość pomiędzy obserwacją oraz resztą obserwacji z tego samego klastra
b: średnia odległość pomiędzy obserwacją oraz innymi obserwacjami z kolejnego najbliższego klastra
Metryka Silhouette coefficient dla zbioru obserwacji jest średnią z wartości \(s\) dla każdej obserwacji z osobna.
Warto zapamiętać
metryka osiąga wyniki z przedziału [-1, 1], gdzie -1 oznacza zupełnie błędne dopasowanie, a 1 bardzo dobrze podzielone zbiory. W przypadku wartości 0 nie jesteśmy nic w stanie stwierdzić apropo podziału zbioru danych na grupy
wynik jest wyższy, gdy klastry są gęste i dobrze odseparowane od siebie (Przykład 1)
wynik jest wyższy w przypadku klastrów wypukłych (Przykład 1), niż dla innych rodzajów klastrów np. takich opartych na gęstości jak DBSCAN (Przykład 2)
Caliński-Harabasz Index#
from sklearn.metrics import calinski_harabasz_score
Kolejną metryką przydatną w trakcie klastrowania jest mniej popularna metryka Calinski-Harabasz, inaczej zwana Variance Ratio Criterion. Została ona zaproponowana przez Polskich naukowców Calińskiego i Harabasza w 1972 roku. Podobnie jak w przypadku poprzedniej metryki wyższa wartość oznacza lepsze grupowanie danych w klastry. Metrykę Variance Ratio Criterion dla zbioru danych \(E\) o liczbie obserwacji \(n\) oraz liczbie klastrów \(k\) definiujemy w następujacy sposób:
gdzie \(tr(B_{k})\) oraz \(tr(W_{k})\) jest śladem macierzy \(B_{k}\) oraz \(W_{k}\). Dla przypomnienia ślad macierzy \(A\) definiujemy jako:
czyli jest to suma wartości na przekątnej macierzy kwdaratowej. Macierze \(B_{k}\) oraz \(W_{k}\) są wyliczane dla każdego klastra z osobna i mają następująco postać:
gdzie \(C_{q}\) jest zbiorem obserwacji klastra \(q\), \(c_{q}\) jest środkiem klastra \(q\), \(c_{E}\) jest środkiem całego zbioru obserwacj \(E\) oraz \(n_{q}\) jest liczbą obserwacji w klastrze \(q\).
Warto zapamiętać
wartość metryki jest wyższa, gdy klastry są gęste oraz dobrze rozdzielone od siebie
metryka jest szybka do kalkulacji
Davies-Bouldin Index#
from sklearn.metrics import davies_bouldin_score
Ostatnim z analizowanych metryk skuteczności klastrowania jest Davies-Bouldin Index. Metryka mierzy średnie “podobieństwo” między klastrami. Wtedy wartość równa zero jest najniższą osiągana wartością, natomiast 1 najwyższa. Jak nie trudno się domyślić chcemy aby klastry był jak najmniej do siebie podobne stąd interesuje nas jak najniższa wartość tej metryki.
Davies-Bouldin Index definiujemy jako średnie podobieństwo między klastrami \(C_{i}\) dla \(i=1, 2, ..., k\) oraz najbardziej podobnym klastrem \(C_{j}\). Podobieństwo jest definiowane za pomocą wartości \(R_{ij}\) oraz wzoru:
gdzie:
\(s_{i}\) jest średnią odległością pomiędzy każdą z obserwacji klastra \(i\) oraz centroidu tego klastra
\(d_{ij}\) jest odległością pomiędzy centroidami klastrów \(i\) oraz \(j\)
Wtedy Davies-Bouldin Index ma następującą postać:
Warto zapamiętać
kalkulacja tej metryki Davies-Bouldin index jest prostsza niż Silhouette coefficient
podobnie jak poprzednie metody Davies-Bouldin index osiąga lepsze wyniki dla klastrów wypukłych, lepiej odseparowanych od siebie niż dla metod opartych o gęstość jak DBSCAN.
Dunn Index#
…
Przykłady (analiza skuteczności)#
Przykład 1#
Poniżej widoczne są 3 rodzaje klastrowania. Wizualizacja 1 jest wynikiem klastrowania KMeans z inicjalizacją random dla trzech klastrów. Dodatkowo w tym przypadku stosujemy tylko jedną iteracje algorytmu aby wynik był niezadawalający. Kolejne wizualizacja jest wynikiem algorytmu KMeans++ z trzema klastrami, zaś ostatnia to wynik KMeans++ z czterama klastrami. Gołym okiem widać, że drugi rodzaj klastrowania jest najlepszy. Jak wyglądają wyniki względem metryki Silhouette coeffcient ? Wartość najwyższa jest osiągana dla drugiego algorytmu - tak jak się spodziewaliśmy. Dużo niższe wyniki są dla algorytmu pierwszego i trzeciego. To pokazuję na siłę tej metryki, która oprócz informacji jaki algorytm wybrać (KMeans z inicjalizacją random czy Kmeans++) to dodatkowo może pomóc nam w wyborze liczby klastrów dla naszych danych (3 a może 4?). Najczęściej w tego typu przypadkach jest wykorzystywana ta metryka.
np.random.seed(100)
algorithms = ['KMEANS_RANDOM', 'KMEANS++(3)', 'KMEANS++(4)']
eval_times = []
silh_distances = []
calinski_distances = []
db_distances = []
shape_X = X_2.shape
# K-means random, ncluster=3
tic = dt.datetime.now()
model_random = KMeans(n_clusters=3, init='random', n_init=1, max_iter=1)
model_random.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_random = model_random.predict(X_2)
silh_dist = silhouette_score(X_2, y_cluster_random, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_2, y_cluster_random)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_2, y_cluster_random)
db_distances.append(db_dist)
# K-means++, ncluster=3
tic = dt.datetime.now()
model_plusplus = KMeans(n_clusters=3, init='k-means++')
model_plusplus.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus = model_plusplus.predict(X_2)
silh_dist = silhouette_score(X_2, y_cluster_plusplus, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_2, y_cluster_plusplus)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_2, y_cluster_plusplus)
db_distances.append(db_dist)
# K-means++, ncluster=4
tic = dt.datetime.now()
model_plusplus4 = KMeans(n_clusters=4, init='k-means++')
model_plusplus4.fit(X_2)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plusplus4 = model_plusplus4.predict(X_2)
silh_dist = silhouette_score(X_2, y_cluster_plusplus4, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_2, y_cluster_plusplus4)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_2, y_cluster_plusplus4)
db_distances.append(db_dist)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_random, ax=ax[0])
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_plusplus, ax=ax[1])
sns.scatterplot(x=X_2[:, 0], y=X_2[:, 1], hue=y_cluster_plusplus4, ax=ax[2])
ax[0].set_title('Klastrowanie KMeans z inicjalizacja random \n(ncluster=3)')
ax[1].set_title('Klastrowanie KMeans z inicjalizacją k-means++ \n(ncluster=3)')
ax[2].set_title('Klastrowanie KMeans z inicjalizacją k-means++ \n(ncluster=4)')
plt.suptitle('Obserwacje X_2 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Czas kalkulacji / Silhouette score / Calinski-Harabasz score / Davies-Boulding index
print(f'Data frame shape: {shape_X}')
print('\n')
for algorithm, etime, silh, cali, db in zip(algorithms, eval_times, silh_distances, calinski_distances, db_distances):
print(f'-----------[{algorithm}]-----------')
print(f'Duration: {etime}')
print(f'Silhouette coeffcient: {silh}')
print(f'Calinski-Harabasz coeffcient: {cali}')
print(f'Davies-Bouldin index: {db}')
print('\n')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=6.
warnings.warn(
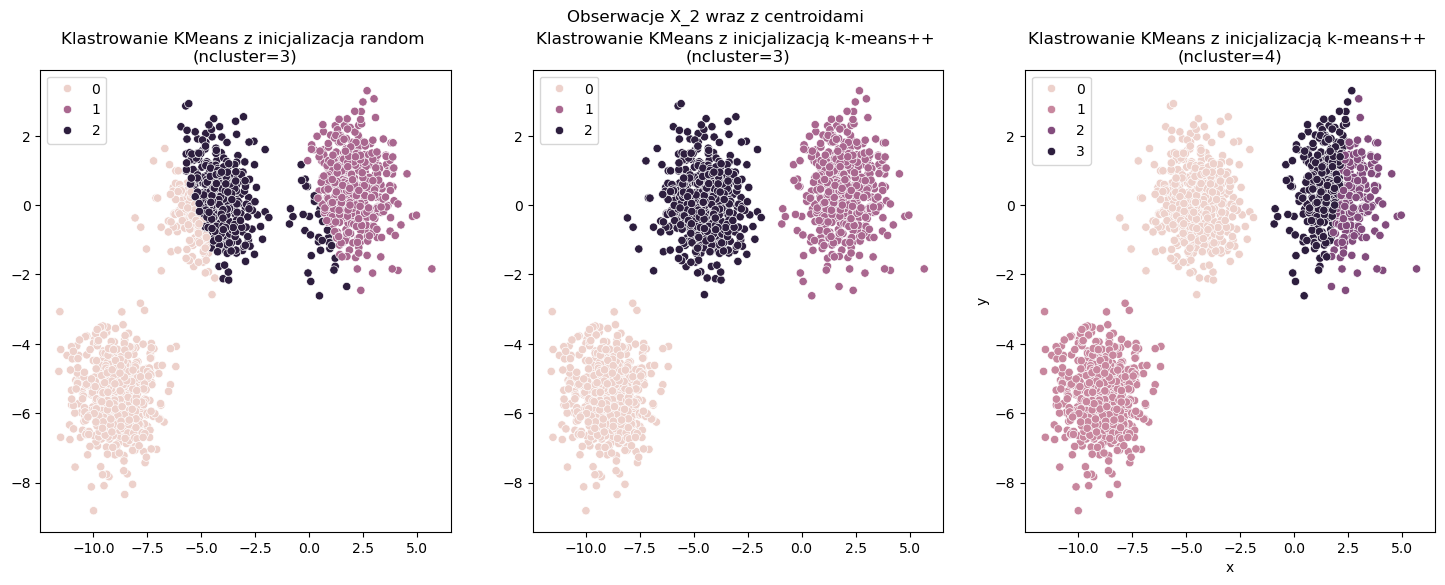
Data frame shape: (1500, 2)
-----------[KMEANS_RANDOM]-----------
Duration: 0:00:00.011561
Silhouette coeffcient: 0.5552189244037514
Calinski-Harabasz coeffcient: 3926.26945406362
Davies-Bouldin index: 0.5415468489574247
-----------[KMEANS++(3)]-----------
Duration: 0:00:00
Silhouette coeffcient: 0.7333423486262539
Calinski-Harabasz coeffcient: 10633.868943793219
Davies-Bouldin index: 0.3645102673195062
-----------[KMEANS++(4)]-----------
Duration: 0:00:00.015627
Silhouette coeffcient: 0.5817871280263665
Calinski-Harabasz coeffcient: 7945.133454263886
Davies-Bouldin index: 0.8169579224359983
Przykład 2#
Niestety nie zawsze powyższe metryki się sprawdzają. W poniższym przykładzie porównujemy między sobą 3 kklastrowania: KMeans++, Spectral Clustering oraz DBSCAN. Każda z tych metod dzieli obserwacje w innym sposób. Wydaję się, że najgorzej robi to metoda KMeans++, natomiast Spectral Clustering oraz DBSCAN działają podobnie, choć DBSCAN wskazuję nam jeszcze pewne anomalie w naszych danych. Jeśli jednak spojrzymy na wyniki tych metryk to okazuję się, że żadna z trzech metryk nie odpowie nam na pytanie, które z tych klastrowań jest poprawne. W tego typu problemach, gdzie klastry nie charakteryzują się rozkładem normalnym metryka każda z tych metryk nie do końca zda egzamin.
np.random.seed(100)
algorithms = ['KMEANS++', 'SPECTRAL_RBF', 'DBSCAN']
eval_times = []
silh_distances = []
calinski_distances = []
db_distances = []
shape_X = X_1.shape
# KMeans++
tic = dt.datetime.now()
model_kmeans = KMeans(n_clusters=2, init='k-means++')
model_kmeans.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_plus_plus = model_kmeans.labels_
silh_dist = silhouette_score(X_1, y_cluster_plus_plus, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_1, y_cluster_plus_plus)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_1, y_cluster_plus_plus)
db_distances.append(db_dist)
# Spectral Clustering (RBF)
tic = dt.datetime.now()
model_sc = SpectralClustering(n_clusters=2, gamma=10.0, affinity='rbf', assign_labels='kmeans')
model_sc.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_spectral_rbf = model_sc.labels_
silh_dist = silhouette_score(X_1, y_cluster_spectral_rbf, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_1, y_cluster_spectral_rbf)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_1, y_cluster_spectral_rbf)
db_distances.append(db_dist)
# Algorytm DBSCAN
tic = dt.datetime.now()
model_dbscan = DBSCAN(eps=0.3, min_samples=10, metric='euclidean')
model_dbscan.fit(X_1)
eval_times.append(dt.datetime.now() - tic)
y_cluster_dbscan = model_dbscan.labels_
silh_dist = silhouette_score(X_1, y_cluster_dbscan, metric='euclidean')
silh_distances.append(silh_dist)
cali_dist = calinski_harabasz_score(X_1, y_cluster_dbscan)
calinski_distances.append(cali_dist)
db_dist = davies_bouldin_score(X_1, y_cluster_dbscan)
db_distances.append(db_dist)
# Wizualizacja
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(18, 6))
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_plus_plus, ax=ax[0])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_spectral_rbf, ax=ax[1])
sns.scatterplot(x=X_1[:, 0], y=X_1[:, 1], hue=y_cluster_dbscan, ax=ax[2])
ax[0].set_title('Klastrowanie KMeans++')
ax[1].set_title('Klastrowanie Spectral Clustering (RBF)')
ax[2].set_title('Klastrowanie DBSCAN')
plt.suptitle('Obserwacje X_1 wraz z centroidami')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
# Czas kalkulacji / Silhouette score / Calinski-Harabasz score / Davies-Boulding index
print(f'Data frame shape: {shape_X}')
print('\n')
for algorithm, etime, silh, cali, db in zip(algorithms, eval_times, silh_distances, calinski_distances, db_distances):
print(f'-----------[{algorithm}]-----------')
print(f'Duration: {etime}')
print(f'Silhouette coeffcient: {silh}')
print(f'Calinski-Harabasz coeffcient: {cali}')
print(f'Davies-Bouldin index: {db}')
print('\n')
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
C:\Users\knajmajer\AppData\Local\anaconda3\envs\jbook\Lib\site-packages\sklearn\cluster\_kmeans.py:1429: UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=4.
warnings.warn(
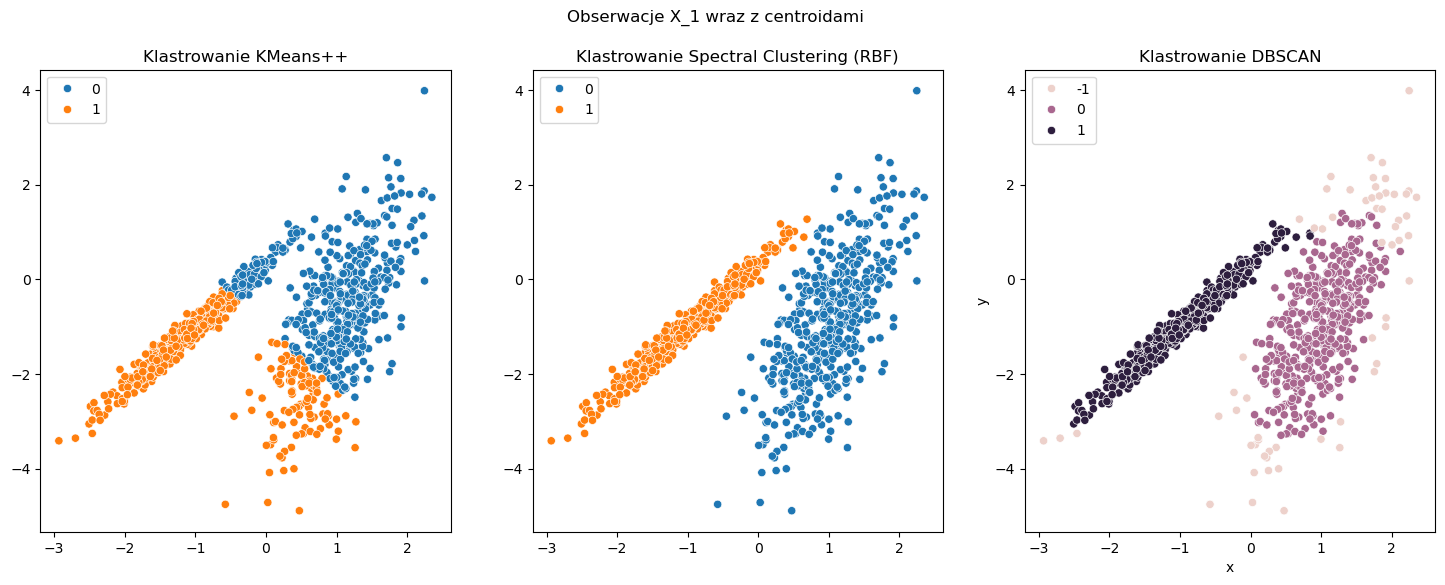
Data frame shape: (1000, 2)
-----------[KMEANS++]-----------
Duration: 0:00:00
Silhouette coeffcient: 0.4271848670924971
Calinski-Harabasz coeffcient: 886.9516041548748
Davies-Bouldin index: 0.9325615075331334
-----------[SPECTRAL_RBF]-----------
Duration: 0:00:00.357377
Silhouette coeffcient: 0.42967355323274
Calinski-Harabasz coeffcient: 658.0643390191713
Davies-Bouldin index: 0.9970552748687121
-----------[DBSCAN]-----------
Duration: 0:00:00.015862
Silhouette coeffcient: 0.4157241178607082
Calinski-Harabasz coeffcient: 310.90990033808214
Davies-Bouldin index: 10.006292286691144
W zależności od problemu do identyfikacji czy nasze klastry są dobrane poprawnie można wykorzystać uczenie maszynowe. W powyższym przykładzie wydaję się zastosowanie regresji liniowej dla zmiennej \(x\) względem zmiennej celu \(y\) pozwoliło by sprawdzić jak podstawowy model wyjaśni nam takie dane. Jeśli model działajacy na klastrach działa lepiej niż dla wszystkich obserwacji to można przypuszczać, że nasze klastrowanie jest dobre. Porównując się do róznych metod kalstrowanie można wtedy badać błędy MAE, RMSE czy R2.
Twoim zadaniem będzie przeprowadzenie analizy danych sprzedażowych sklepów z uwzględnieniem sezonowości. Na początku należy wczytać dane i przygotować je w taki sposób, aby możliwe było obliczenie statystyk sprzedaży w podziale na sezony. Następnie stwórz dodatkowe cechy opisujące działalność sklepów, które mogą być przydatne w dalszej analizie. Nie zapomnij o ustandaryzowaniu danych, by zapewnić ich porównywalność. Kolejnym krokiem będzie przeprowadzenie analizy klastrowej – najpierw określ optymalną liczbę klastrów, przy uzyciu jednej poznanej metody i wybranej metryki. Wyniki klastrowania należy zwizualizować, a na końcu zinterpretować. Opisz, czym charakteryzują się poszczególne klastry i jakie wnioski można wyciągnąć na temat różnych typów sklepów w kontekście sezonowości sprzedaży.
Podpowiedź: Skorzystaj z poznanych bibliotek pandas, sklearn.cluster i sklearn.metrics