NLP#
Wstęp#
Natural Language Processing (NLP), czyli przetwarzanie języka naturalnego, to dziedzina sztucznej inteligencji, która skupia się na interakcji między komputerami a językiem naturalnym używanym przez ludzi. NLP łączy w sobie elementy lingwistyki, informatyki i uczenia maszynowego, a jej celem jest umożliwienie komputerom zrozumienie, interpretowanie oraz generowanie ludzkiej mowy w sposób jak najbardziej zbliżony do ludzkiego. Technologia ta znajduje szerokie zastosowanie w takich dziedzinach jak tłumaczenie maszynowe, analiza sentymentu, chatboty, automatyczne rozpoznawanie mowy czy przetwarzanie tekstu.
Aby komputer mógł zrozumieć i analizować tekst, konieczne jest jego odpowiednie przetworzenie. Proces ten polega na transformacji tekstu na formę, którą komputer jest w stanie analizować i interpretować. Oto kilka z metod przetwarzania tekstu:
Tokenizacja- polega na rozbiciu tekstu na mniejsze jednostki zwane tokenami. Zazwyczaj tokenami są słowa, ale mogą to być także frazy lub zdania.Stemming- proces sprowadzania słów do ich podstawowej formy, zwanej rdzeniem (stem). Stemming usuwa końcówki fleksyjne (np. „przetwarzać” -> „przetwarz”).Lematyzacja- bardziej czasochłonna i zaawansowana metoda niż stemming. Polega na sprowadzeniu słowa do jego formy podstawowej, czyli lematu (np. „przetwarzający” -> „przetwarzać”).Bag of Words (BoW)- metoda reprezentacji tekstu, w której dokument jest traktowany jako zbiór słów, biorąc pod uwagę ich częstotliwość występowania. Przydatne w problemach takich jak klasyfikacja tekstu czy analiza sentymentu, gdzie ważna jest obecność słów kluczowych, a nie ich kolejność.TF-IDF (Term Frequency-Inverse Document Frequency)- metoda oceny wagę słowa w dokumencie w kontekście całego zbioru. TF (częstotliwość terminu) mierzy, jak często dane słowo pojawia się w tekście, natomiast IDF (odwrotna częstotliwość dokumentów) ocenia, jak unikalne jest dane słowo w zbiorze dokumentów.Rozpoznawanie części mowy (POS Tagging)- polega na automatycznym przypisaniu słowom w tekście ich odpowiednich części mowy (rzeczownik, czasownik, przymiotnik itp.).Word Embeddings- metoda reprezentowania słów w postaci wektorów liczbowych w przestrzeni wielowymiarowej, która uwzględnia semantykę słów. Popularne metody to Word2Vec, GloVe czy FastText.Transformery i modele głębokie- modele oparte na architekturze transformatorów, takie jak BERT czy GPT, umożliwiają analizowanie całych sekwencji tekstu, biorąc pod uwagę kontekst słów. Transformery używają mechanizmów uwagi (attention), aby modelować relacje między słowami w zdaniach niezależnie od ich odległości od siebie.
W związku z trudniejszym dostępem do zbioru danych w języku polskim, w poniższym tutorialu wykorzystywany będzie zbiór w języku angielskim, a wybrane metody przetwarzania tekstu będą przedstawiane również w języku polskim na przykładowych zdaniach.
Do przetwarzania języka polskiego będziemy korzystać głównie z biblioteki SpaCy, używanej do przetwarzania języka naturalnego i metod takich jak POS tagging, lematyzacja i tokenizacja. Kolejną popularną biblioteką do NLP jest NLTK, ale niestety język polski nie jest przez nią wspierany.
# libraries
from time import time
import multiprocessing
import pandas as pd
import spacy
from spacy.lang.pl.examples import sentences
from string import punctuation
from spacy.lang.pl import stop_words
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
import re
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
import gensim
from gensim.models import Word2Vec, KeyedVectors
import gensim.downloader
import gensim
import os
from gensim.test.utils import datapath
from nltk import sent_tokenize
from gensim.utils import simple_preprocess
from gensim.models import Word2Vec
import logging
logging.basicConfig(format="%(levelname)s - %(asctime)s: %(message)s", datefmt= '%H:%M:%S', level=logging.INFO)
import plotly.express as px
from sklearn.decomposition import PCA
from transformers import AutoTokenizer, AutoModel
import torch
nlp = spacy.load("pl_core_news_sm") # wykonujemy uprzednio python -m spacy download pl_core_news_sm
doc = nlp(sentences[0])
print(doc.text)
Poczuł przyjemną woń mocnej kawy.
for token in doc:
print(token.text, token.pos_, token.dep_)
Poczuł VERB ROOT
przyjemną ADJ amod
woń NOUN iobj
mocnej ADJ amod
kawy NOUN nmod:arg
. PUNCT punct
sentences
['Poczuł przyjemną woń mocnej kawy.',
'Istnieje wiele dróg oddziaływania substancji psychoaktywnej na układ nerwowy.',
'Powitał mnie biało-czarny kot, płosząc siedzące na płocie trzy dorodne dudki.',
'Nowy abonament pod lupą Komisji Europejskiej',
'Czy w ciągu ostatnich 48 godzin spożyłeś leki zawierające paracetamol?',
'Kto ma ochotę zapoznać się z innymi niż w książkach przygodami Muminków i ich przyjaciół, temu polecam komiks Tove Jansson „Muminki i morze”.']
Normalizacja danych tekstowych#
Znaki interpunkcyjne#
punctuations = list(punctuation)
print(punctuations)
['!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '@', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~']
# removing punctuations
def remove_punctuation(tekst):
return tekst.translate(str.maketrans('', '', punctuation))
text = "Przykładowe 'zdanie' [ze] znakami: interpunkcyjnymi...!?"
print(f"Input: {text}")
print(f"Output: {remove_punctuation(text)}")
Input: Przykładowe 'zdanie' [ze] znakami: interpunkcyjnymi...!?
Output: Przykładowe zdanie ze znakami interpunkcyjnymi
Konwersja na małe litery#
# converting to lowercase
def convert_to_lowercase(tekst):
return tekst.lower()
text = "SUPER Super supeR super"
print(f"Input: {text}")
print(f"Output: {convert_to_lowercase(text)}")
Input: SUPER Super supeR super
Output: super super super super
Usuwanie stop-wordsów#
Usunięcie stop-wordsów z danych tekstowych zmniejsza wymiarowość danych i zwiększa wydajność, a czasami także skuteczność algorytmów. Na przykład, usunięcie ich z dokumentu może pomóc w klasyfikacji tekstu, kiedy chcemy skupić się na najważniejszych i najbardziej istotnych słowach, dzięki którym algorytm będzie w stanie przypisać tekst do odpowiedniej kategorii. Należy jednak pamiętać, że słowa te nie zawsze są nieistotne, a w niektórych przypadkach wykluczenie stop-wordsów może wpłynąć na cały kontekst zdania. Dlatego ważne jest, aby starannie przemyśleć, czy i w jaki sposób uwzględniać stop-wordsy w naszym problemie.
Zalety
Zmniejszenie rozmiaru danych tekstowych, co sprawia, że są one łatwiejsze do zarządzania i szybsze w przetwarzaniu.
Poprawa wydajności algorytmów przetwarzania języka naturalnego poprzez redukcję nieistotnych słów.
Zwiększenie przejrzystości i zrozumiałości wyników poprzez usunięcie słów, które nie mają większego znaczenia.
Wady
Ryzyko utraty istotnych informacji poprzez usunięcie słów, które mogą mieć znaczenie w określonym kontekście.
Trudności w znalezieniu odpowiednich list stop-wordsów w niektórych językach, co może ograniczać skalowalność w przypadku przetwarzania wielu języków.
Lista stop-wordsów w języku polskim z biblioteki SpaCy:
stopwords = stop_words.STOP_WORDS
print(stopwords)
{'kto', 'dwa', 'jego', 'kiedy', 'u', 'jakiz', 'naszego', 'pod', 'takze', 'czyli', 'dużo', 'gdzieś', 'chce', 'jakie', 'miał', 'mogą', 'zeby', 'gdziekolwiek', 'lub', 'owszem', 'między', 'gdy', 'poniewaz', 'ok', 'być', 'duzo', 'pana', 'raz', 'tak', 'przed', 'też', 'ani', 'zostal', 'bylo', 'wszystkich', 'jej', 'wszystkie', 'jeżeli', 'nasz', 'bowiem', 'choć', 'niej', 'przede', 'zadnych', 'która', 'nasze', 'nad', 'byl', 'tej', 'xiii', 'ach', 'pomimo', 'totez', 'którego', 'jakiś', 'wasze', 'już', 'było', 'bym', 'dla', 'wiele', 'jakichs', 'iv', 'ich', 'bede', 'swoje', 'ktory', 'w', 'niego', 'sam', 'również', 'dokad', 'także', 'my', 'dobrze', 'to', 'według', 'bez', 'sposób', 'podczas', 'ten', 'dlaczego', 'jak', 'sposob', 'byla', 'często', 'tu', 'byli', 'który', 'można', 'xiv', 'za', 'ktos', 'nas', 'prawie', 'kims', 'wasza', 'sie', 'zadna', 'żadnych', 'cali', 'acz', 'ile', 'przecież', 'nigdy', 'nimi', 'aczkolwiek', 'godz', 'jakkolwiek', 'twoj', 'nasza', 'cos', 'obok', 'ktoś', 'musi', 'oni', 'którzy', 'bynajmniej', 'powinni', 'jakaś', 'xii', 'jednakze', 'juz', 'zaden', 'jednakże', 'vi', 'moze', 'co', 'mało', 'kimś', 'cały', 'jeden', 'wlasnie', 'mój', 'nic', 'on', 'żeby', 'dosc', 'ze', 'jeszcze', 'zaś', 'może', 'na', 'niż', 'no', 'vii', 'razie', 'którym', 'czemu', 'bardziej', 'iż', 'trzeba', 'znów', 'wasz', 'tobie', 'pan', 'sama', 'ix', 'natychmiast', 'został', 'od', 'jeśli', 'byly', 'cie', 'kilku', 'były', 'żadne', 'coś', 'bo', 'będą', 'mają', 'coraz', 'cala', 'aby', 'nia', 'rowniez', 'moja', 'ma', 'wtedy', 'ponieważ', 'wami', 'tym', 'skąd', 'one', 'kilka', 'natomiast', 'je', 'taki', 'ja', 'jezeli', 'jestem', 'temu', 'czasem', 'do', 'moga', 'których', 'roku', 'mozliwe', 'mną', 'inne', 'wśród', 'przeciez', 'we', 'wszystko', 'wszyscy', 'właśnie', 'inny', 'poza', 'aż', 'pani', 'tylko', 'możliwe', 'dzis', 'jakichś', 'go', 'jaki', 'ktorego', 'będzie', 'dość', 'was', 'nawet', 'ci', 'tel', 'dwaj', 'jedna', 'toba', 'jednak', 'albo', 'nią', 'ta', 'zadne', 'twoja', 'gdzies', 'wszystkim', 'o', 'i', 'tobą', 'daleko', 'ktore', 'miedzy', 'moj', 'twoi', 'twym', 'jakoś', 'jakas', 'około', 'że', 'twoje', 'alez', 'gdyż', 'będę', 'jakby', 'cała', 'czasami', 'której', 'toteż', 'im', 'bardzo', 'kazdy', 'naszych', 'każdy', 'powinno', 'znowu', 'zapewne', 'dlatego', 'az', 'ją', 'mimo', 'a', 'nasi', 'mam', 'nim', 'powinna', 'jakiż', 'ktorym', 'innych', 'powinien', 'mamy', 'nami', 'mu', 'ku', 'tego', 'ktorej', 'nam', 'tutaj', 'jednym', 'ktora', 'jedno', 'gdzie', 'jakos', 'oraz', 'teraz', 'więcej', 'sobą', 'jakis', 'caly', 'te', 'jedynie', 'moi', 'wy', 'dokąd', 'przez', 'byc', 'dzisiaj', 'wielu', 'tych', 'mozna', 'dwoje', 'znow', 'żaden', 'soba', 'takie', 'wam', 'się', 'ktokolwiek', 'są', 'ależ', 'moim', 'z', 'inna', 'nie', 'twój', 'ciebie', 'xi', 'żadna', 'bedzie', 'ono', 'ty', 'sobie', 'dwie', 'niech', 'iz', 'jemu', 'dziś', 'jako', 'ponad', 'przedtem', 'niemu', 'viii', 'tam', 'wie', 'mi', 'cokolwiek', 'więc', 'jest', 'ktorych', 'które', 'taka', 'cię', 'tys', 'beda', 'ale', 'tzw', 'wasi', 'kierunku', 'lecz', 'xv', 'twoim', 'gdyz', 'po', 'oto', 'aj', 'totobą', 'był', 'moje', 'tę', 'czy', 'ona', 'gdyby', 'skad', 'zawsze', 'była', 'takich', 'by', 'przy', 'ktorzy', 'mna', 'jesli', 'nich', 'niz', 'mnie'}
# removing stop-words using SpaCy
def remove_stopwords(tekst):
doc = nlp(tekst)
removed = " ".join([token.text for token in doc if not token.is_stop])
return removed
text = "Kto ma ochotę zapoznać się z innymi niż w książkach przygodami Muminków i ich przyjaciół, temu polecam komiks Tove Jansson „Muminki i morze”."
print(f"Input: {text}")
print(f"Output: {remove_stopwords(text)}")
Input: Kto ma ochotę zapoznać się z innymi niż w książkach przygodami Muminków i ich przyjaciół, temu polecam komiks Tove Jansson „Muminki i morze”.
Output: ochotę zapoznać innymi książkach przygodami Muminków przyjaciół , polecam komiks Tove Jansson „ Muminki morze ” .
Lematyzacja, stemming#
Lematyzacja i stemming to dwie techniki przetwarzania języka naturalnego (NLP), które pozwalają na sprowadzanie wyrazów do ich skróconych form.
Lematyzacja polega na sprowadzeniu wyrazu do jego lematu, czyli formy podstawowej. Proces ten uwzględnia reguły gramatyczne danego języka, co sprawia, że lematyzacja jest bardziej precyzyjna niż stemming. Stemming to prostsza technika, która polega na obcięciu końcówek wyrazów w celu sprowadzenia ich do wspólnego trzonu (rdzenia), bez dbania o poprawność gramatyczną. Stemming jest szybszy niż lematyzacja, ale mniej precyzyjny.
Dla języka polskiego istnieje kilka bibliotek i narzędzi, które wspierają lematyzację oraz stemming:
Morfeusz2 (lematyzacja)
Morfeusz2 to zaawansowane narzędzie służące do analizy morfologicznej języka polskiego, rozwijane przez Instytut Podstaw Informatyki PAN. Jest to narzędzie wspierające lematyzację, które pozwala rozpoznawać podstawową formę wyrazu i jego kategorie gramatyczne. Dokumentacja: http://morfeusz.sgjp.pl/
Stempel (stemming)
Stempel to algorytm stemmingowy dla języka polskiego oparty na bibliotece Lucene, który został zaimplementowany w Pythonie. Jest to stemming specyficznie zaprojektowany z myślą o polskim, który lepiej radzi sobie z złożonością tego języka niż proste algorytmy obcinające końcówki.
SpaCy (lematyzacja)
# lemmatization using SpaCy
text = "Nie ma rzeczy niemożliwych, są tylko trudne do zrealizowania."
doc = nlp(text)
print(f"Input: {text}")
print(f"Output: {" ".join([token.lemma_ for token in doc])}")
Input: Nie ma rzeczy niemożliwych, są tylko trudne do zrealizowania.
Output: nie mieć rzecz niemożliwy , być tylko trudny do zrealizować .
def lemmatization(tekst):
nlp = spacy.load("pl_core_news_sm")
doc = nlp(tekst)
return " ".join([token.lemma_ for token in doc])
Porównajmy jak działa lematyzacja i stemming w języku angielskim:
# lemmatization using SpaCy in english
nlp_en = spacy.load("en_core_web_sm")
text = "Dogs are barking loudly in the distance."
doc = nlp_en(text)
print(f"Input: {text}")
print(f"Output: {" ".join([token.lemma_ for token in doc])}")
Input: Dogs are barking loudly in the distance.
Output: dog be bark loudly in the distance .
import nltk
nltk.download('punkt_tab')
[nltk_data] Downloading package punkt_tab to
[nltk_data] C:\Users\knajmajer\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\punkt_tab.zip.
True
# stemming using NLTK in english
ps = PorterStemmer()
text = "Dogs are barking loudly in the distance."
words = word_tokenize(text)
print(f"Input: {text}")
print(f"Output: {" ".join([ps.stem(word) for word in words])}")
Input: Dogs are barking loudly in the distance.
Output: dog are bark loudli in the distanc .
Oprócz przedstawionych wyżej metod, istnieją także inne istotne techniki przetwarzania tekstu, które mogą być przydatne w różnych zadaniach związanych z analizą tekstu. Do tych metod należą m.in.:
usuwanie białych znaków,
usuwanie emotikonów,
usuwanie linków i adresów URL,
usuwanie liczb i symboli,
rozwijanie akronimów, np. “dr”, “mgr”, “m.in.”, “np.”,
korekta ortografii.
Wszystkie te techniki mają na celu poprawę jakości danych i ułatwienie dalszej analizy tekstu, zwłaszcza w kontekście przetwarzania języka naturalnego (NLP).
def text_normalization(tekst):
tekst = convert_to_lowercase(tekst)
tekst = lemmatization(tekst)
tekst = remove_punctuation(tekst)
tekst = remove_stopwords(tekst)
tekst = " ".join(re.split(r"\s+", tekst, flags=re.UNICODE)) # remove duplicated whitespaces
return tekst
text_normalization("Nie ma rzeczy niemożliwych, są tylko trudne do zrealizowania.")
'mieć rzecz niemożliwy trudny zrealizować'
Wektoryzacja#
Algorytmy wymagają danych numerycznych, najczęściej w postaci dwuwymiarowej macierzy. Problem z językiem naturalnym polega na tym, że dane występują w formie surowego tekstu, który musi zostać przekształcony w wektor. Proces ten nazywany jest wektoryzacją tekstu i stanowi kluczowy etap w przetwarzaniu języka naturalnego.
Bag of Words#
Bag of Words (BoW) - metoda ta polega na prostym zliczaniu częstotliwości występowania słów w dokumencie. Powstały wektor dla danego dokumentu zawiera liczbę wystąpień każdego słowa w korpusie.
CountVectorizer z biblioteki scikit-learn, realizuje jednocześnie tokenizację dokumentu, jak i zliczanie wystąpień danego słowa w dokumencie.
corpus = ['Lubię czytać o NLP', 'Nie lubię czytać książek', 'Lubię NLP', 'Lubię NLP, NLP jest super!', 'W lato jest ciepło.']
vectorizer = CountVectorizer(ngram_range=(1, 2))
X = vectorizer.fit_transform(corpus)
print(f"Tokeny: {vectorizer.get_feature_names_out()}")
print("\n")
print(X.toarray())
Tokeny: ['ciepło' 'czytać' 'czytać książek' 'czytać nlp' 'jest' 'jest ciepło'
'jest super' 'książek' 'lato' 'lato jest' 'lubię' 'lubię czytać'
'lubię nlp' 'nie' 'nie lubię' 'nlp' 'nlp jest' 'nlp nlp' 'super']
[[0 1 0 1 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0]
[0 1 1 0 0 0 0 1 0 0 1 1 0 1 1 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0]
[0 0 0 0 1 0 1 0 0 0 1 0 1 0 0 2 1 1 1]
[1 0 0 0 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0]]
Każde zliczone wystąpienie danego słowa traktowane jest jako cecha do modelu.
TF-IDF#
Jednym z najpopularniejszych algorytmów wektoryzacji tekstu jest TF-IDF, szeroko stosowany w tradycyjnych algorytmach uczenia maszynowego, który pomaga przekształcić tekst w wektory.
TF-IDF (Term Frequency–Inverse Document Frequency) jest jednym ze sposobów na przeprowadzenie wektoryzacji. Zwracany jest wektor, w którym każdy wymiar odpowiada danemu słowu w słowniku. Każdy składnik tego wektora odzwierciedla częstotliwość występowania danego słowa w porównaniu z całą kolekcją tekstów. Metoda ta nie uwzględnia jednak kolejności słów w tekście i ignoruje semantyczne podobieństwo między nimi. Ponadto nie rozróżnia różnych znaczeń polisemicznych słów (np. „dźwięk” w zdaniach: „głośny dźwięk”, „brzmi poprawnie” czy „rozsądna propozycja”).”
Wartość TF-IDF oblicza się ze wzoru:
\( (tf-idf)_{i,j} = tf_{i,j} \times idf_i,\)
gdzie \(tf_{i,j}\) to tzw. “term frequency”, wyrażone wzorem:
\(tf_{i,j} = \frac{n_{i,j}}{\sum_k n_{k,j}},\)
gdzie \(n_{i,j}\) jest liczbą wystąpień termu \((t_i)\) w dokumencie \(d_j\). Miara \(idf_i\) (inverse document frequence), wyrażana jest następująco:
\(idf_i = log \frac{|D|}{|\{d: t_i \in d\}|},\)
gdzie \(|D|\) - liczba dokumentów w korpusie, \(|\{d: t_i \in d\}|\) - liczba dokumentów zawierających przynajmniej jedno wystąpienie danego termu.
Korzystając z TfidfVectorizer z biblioteki scikit-learn, nie trzeba ręcznie tokenizować tekstu przed przekazaniem go do wektoryzatora. TfidfVectorizer oferuje wbudowane funkcje, które automatycznie dokonują tokenizacji i wstępnego przetwarzania tekstu.
Tokenizacja w TfidfVectorizer#
Tokenizacja: W domyślnej konfiguracji TfidfVectorizer dzieli tekst na słowa, ignorując przy tym znaki interpunkcyjne oraz białe znaki. Działa to na bazie wyrażenia regularnego, które określa, co kwalifikuje się jako token (czyli słowo). Domyślny wzorzec r"(?u)\b\w\w+\b" wychwytuje sekwencje alfanumeryczne (słowa) o długości co najmniej dwóch znaków. Ten wzorzec można dostosować za pomocą parametru token_pattern. Chociaż spacje zazwyczaj wskazują, gdzie jedno słowo się kończy, a inne zaczyna, wyrażenie regularne nie dzieli tekstu wyłącznie na podstawie spacji. Zamiast tego wyszukuje alfanumeryczne sekwencje otoczone znakami niebędącymi słowami lub końcami tekstu, co lepiej oddaje nasze intuicyjne rozumienie “pełnych” słów. Taki sposób tokenizacji jest bardziej precyzyjny, ponieważ:
Pomija interpunkcję: Na przykład w wyrażeniu “koniec-zdania.”, kropka nie jest traktowana jako część ostatniego słowa, a wzorzec poprawnie ignoruje ją przy tworzeniu tokenu “zdania”.
Obsługuje złożone przypadki: Nie każde słowo jest idealnie oddzielone spacją. Języki z różnymi systemami pisma czy teksty z interpunkcją, jak myślniki czy apostrofy, mogą wprowadzać dodatkowe komplikacje. Domyślny wzorzec dobrze radzi sobie z takimi złożonymi przypadkami, identyfikując słowa w wielu różnych sytuacjach.
Wstępne przetwarzanie: TfidfVectorizer domyślnie przekształca wszystkie litery na małe (domyślnie lowercase=True) i może przeprowadzać dodatkowe operacje normalizacyjne, takie jak usuwanie akcentów.
Opcje dostosowywania#
Niestandardowy tokenizator: można użyć własnej funkcji tokenizującej za pomocą parametru
tokenizer. Funkcja ta przyjmuje jako wejście ciąg tekstu i zwraca listę tokenów.Niestandardowe wstępne przetwarzanie: można również dostarczyć własną funkcję do wstępnej obróbki tekstu poprzez parametr
preprocessor. Funkcja ta przyjmuje tekst jako wejście i zwraca przetworzony ciąg, który następnie podlega tokenizacji.
Ważnym parametrem jest ngram_range - parametr ten definiuje zakres n-gramów, które zostaną uwzględnione przy zliczaniu tokenów. Ustawienie (1, 3) oznacza, że wektoryzator będzie brał pod uwagę unigramy (pojedyncze słowa), bigramy (pary kolejnych słów) oraz trigramy (trzy kolejne słowa) jako indywidualne cechy do wektoryzacji. Innymi słowy, podczas tworzenia wektorów, analizowane będą zarówno pojedyncze słowa, jak i pary oraz trójki słów pojawiających się obok siebie. To podejście pozwala uchwycić bardziej złożone zależności między słowami w tekście, co może znacząco poprawić jakość modelu.
Więcej parametrów można znaleźć w dokumentacji https://scikit-learn.org/1.5/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html.
# tfidf vectorizer from scikit-learn
vectorizer = TfidfVectorizer(ngram_range = (1,2), sublinear_tf=True)
X = vectorizer.fit_transform(corpus)
print(f"Tokeny: {vectorizer.get_feature_names_out()}")
print("\n")
print(f"Shape: {X.shape}")
Tokeny: ['ciepło' 'czytać' 'czytać książek' 'czytać nlp' 'jest' 'jest ciepło'
'jest super' 'książek' 'lato' 'lato jest' 'lubię' 'lubię czytać'
'lubię nlp' 'nie' 'nie lubię' 'nlp' 'nlp jest' 'nlp nlp' 'super']
Shape: (5, 19)
# get the first vector out (for the first document)
first_vector_tfidfvectorizer = X[0]
# place tf-idf values in a data frame
df = pd.DataFrame(first_vector_tfidfvectorizer.T.todense(), index=vectorizer.get_feature_names_out(), columns=["tfidf"])
df['tfidf_2'] = (X[1].T.todense())
df['tfidf_3'] = (X[2].T.todense())
df['tfidf_4'] = (X[3].T.todense())
df['tfidf_5'] = (X[4].T.todense())
display(df.sort_values(by=["tfidf"], ascending = False).T)
| czytać nlp | lubię czytać | czytać | nlp | lubię | ciepło | nlp nlp | nlp jest | nie lubię | nie | lubię nlp | lato jest | lato | książek | jest super | jest ciepło | jest | czytać książek | super | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| tfidf | 0.57094 | 0.460631 | 0.460631 | 0.382365 | 0.321658 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| tfidf_2 | 0.00000 | 0.340349 | 0.340349 | 0.000000 | 0.237665 | 0.000000 | 0.000000 | 0.000000 | 0.421853 | 0.421853 | 0.000000 | 0.000000 | 0.000000 | 0.421853 | 0.000000 | 0.000000 | 0.000000 | 0.421853 | 0.000000 |
| tfidf_3 | 0.00000 | 0.000000 | 0.000000 | 0.562638 | 0.473309 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.677803 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| tfidf_4 | 0.00000 | 0.000000 | 0.000000 | 0.431520 | 0.214398 | 0.000000 | 0.380555 | 0.380555 | 0.000000 | 0.000000 | 0.307030 | 0.000000 | 0.000000 | 0.000000 | 0.380555 | 0.000000 | 0.307030 | 0.000000 | 0.380555 |
| tfidf_5 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.463693 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.463693 | 0.463693 | 0.000000 | 0.000000 | 0.463693 | 0.374105 | 0.000000 | 0.000000 |
Metody Bag of Words oraz TF-IDF nie sprawdzają się zbyt dobrze, gdy w tekstach pojawiają się drobne zmiany terminologiczne. Mamy wtedy zdania o podobnym znaczeniu, lecz używające różnych słów.
Powoduje to powstanie wektorów z wieloma zerowymi wartościami, zwanych wektorami rzadkimi (sparse vectors) lub rzadką reprezentacją. Wektory rzadkie wymagają większej ilości pamięci i zasobów obliczeniowych podczas modelowania, a ogromna liczba wymiarów może spowodować, że tradycyjne algorytmy będą miały trudności z przetwarzaniem tych danych. Dlatego kluczowe jest zmniejszenie rozmiaru słownika słów uniknalnych, np. poprzez usunięcie stop-wordsów, aby zoptymalizować proces modelowania.
Embeddings#
Word embeddings to reprezentacje słów, które uchwytują ich konteksty i podobieństwa poprzez zakodowanie w przestrzeni wektorowej - słowa o zbliżonym znaczeniu mają podobne wektory.
Standardowe procesy normalizacji tekstu, takie jak stemming, lematyzacja czy usuwanie stop-wordsów, nie są zalecane w przypadku używania wstępnie wytrenowanych embeddingów. Etapy te mogą powodować utratę cennych informacji, które mogłyby zostać wykorzystane przez sieć neuronową.
Word2Vec#
Word2Vec to popularny algorytm używany w przetwarzaniu języka naturalnego (NLP), którego głównym celem jest przekształcanie słów w numeryczne reprezentacje - wektory. Został opracowany przez Google w 2013 roku.
Algorytm Word2Vec wykorzystuje dwuwarstwową sieć neuronową (nie głęboką), aby przetworzyć korpus tekstu i wygenerować zestawy wektorów reprezentujących słowa. Kluczowym założeniem Word2Vec jest to, że słowa pojawiające się w podobnych kontekstach mają podobne znaczenia. Dwa główne podejścia wykorzystywane przez ten algorytm to:
CBOW (Continuous Bag of Words) - Przewiduje słowo na podstawie jego kontekstu, czyli słów otaczających dane słowo w zdaniu.
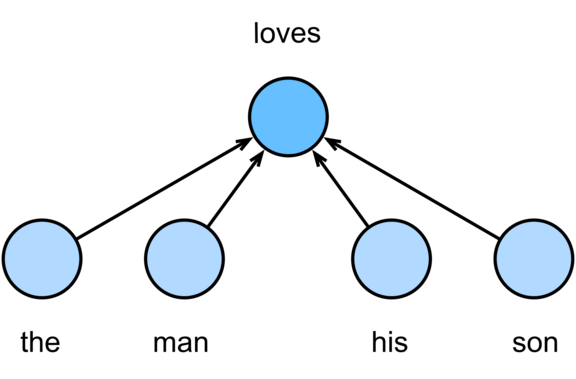
Skip-gram - Przewiduje kontekstowe słowa (słowa otaczające), na podstawie danego słowa.
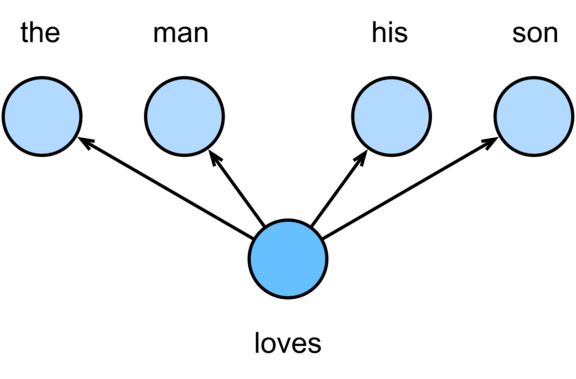
By Zhang, Aston and Lipton, Zachary C. and Li, Mu and Smola, Alexander J. - d2l-ai/d2l-en, CC BY-SA 4.0.
Dane wejściowe zawierają wszystkie dokumenty/teksty z naszego zestawu treningowego. Aby sieć mogła je przetwarzać, teksty są reprezentowane za pomocą 1-hot encodingu. Liczba neuronów w warstwie ukrytej jest równa długości wektora embeddingu, który chcemy uzyskać. Na przykład, jeśli chcemy, aby nasze słowa były reprezentowane jako wektory o długości 300, warstwa ukryta będzie zawierać 300 neuronów. Warstwa wyjściowa generuje prawdopodobieństwa dla słowa docelowego. Na końcu, wagi z warstwy ukrytej są traktowane jako embeddingi. Można to intuicyjnie rozumieć jako przypisanie każdemu słowu zestawu n wag (w tym przykładzie 300).
Korzystanie z modeli wstępnie wytrenowanych#
Biblioteka Gensim oferuje dostęp do wielu wstępnie wytrenowanych modeli. Aby wyświetlić listę modeli wytrenowanych na dużych zbiorach danych, które są dostępne do użycia, możemy skorzystać z poniższej metody. Lista ta obejmuje nie tylko modele typu Word2Vec, ale również takie jak GloVe czy FastText.
Model google-news-300 został wytrenowany na części zbioru danych Google News, obejmującego około 100 miliardów słów. Model zawiera wektory o 300 wymiarach dla 3 milionów słów i fraz.
# show all available models in gensim
print(list(gensim.downloader.info()['models'].keys()))
['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis']
google_news = gensim.downloader.load('word2vec-google-news-300')
INFO - 00:48:19: loading projection weights from C:\Users\knajmajer/gensim-data\word2vec-google-news-300\word2vec-google-news-300.gz
INFO - 00:50:10: KeyedVectors lifecycle event {'msg': 'loaded (3000000, 300) matrix of type float32 from C:\\Users\\knajmajer/gensim-data\\word2vec-google-news-300\\word2vec-google-news-300.gz', 'binary': True, 'encoding': 'utf8', 'datetime': '2026-01-12T00:50:10.192685', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'load_word2vec_format'}
# most similar to dress
google_news.most_similar('dress')
[('dresses', 0.83203125),
('frock', 0.725713312625885),
('attire', 0.7096524834632874),
('gown', 0.7021297216415405),
('cocktail_dress', 0.6975935697555542),
('gowns', 0.6693259477615356),
('dressed', 0.6680650115013123),
('backless_dress', 0.6655371785163879),
('couture_gown', 0.6646832823753357),
('maxi_dress', 0.6581150889396667)]
# most similar to dress and cotton
google_news.most_similar(positive=['dress', 'cotton'], topn=5)
[('dresses', 0.7367835640907288),
('cottons', 0.6351203918457031),
('denim', 0.6321719884872437),
('tunic_tops', 0.6279573440551758),
('peasant_skirt', 0.6216402053833008)]
# words than doesnt match
google_news.doesnt_match(['fire', 'water', 'land', 'sea', 'air', 'car'])
'car'
# measure similarity between woman and man
google_news.similarity('woman', 'man')
0.76640123
# measure similarity between car and apple
google_news.similarity('car', 'apple')
0.12830706
Word2Vec na własnym zbiorze danych#
Dokumentacja: https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec
sntcs = []
corpus_path = datapath('lee_background.cor')
f = open(corpus_path)
corpus = f.read()
raw_sent = sent_tokenize(corpus)
for sent in raw_sent:
sntcs.append(simple_preprocess(sent))
len(sntcs)
2684
cores = multiprocessing.cpu_count()
model = gensim.models.Word2Vec(workers=cores-1) # with default parameters
t = time()
model.build_vocab(sntcs, progress_per=500)
print(f'Czas budowania słownika: {round((time() - t), 2)} s.')
INFO - 00:50:16: Word2Vec lifecycle event {'params': 'Word2Vec<vocab=0, vector_size=100, alpha=0.025>', 'datetime': '2026-01-12T00:50:16.824140', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'created'}
INFO - 00:50:16: collecting all words and their counts
INFO - 00:50:16: PROGRESS: at sentence #0, processed 0 words, keeping 0 word types
INFO - 00:50:16: PROGRESS: at sentence #500, processed 10181 words, keeping 2603 word types
INFO - 00:50:16: PROGRESS: at sentence #1000, processed 21505 words, keeping 4062 word types
INFO - 00:50:16: PROGRESS: at sentence #1500, processed 32282 words, keeping 5048 word types
INFO - 00:50:16: PROGRESS: at sentence #2000, processed 43343 words, keeping 5958 word types
INFO - 00:50:16: PROGRESS: at sentence #2500, processed 54338 words, keeping 6737 word types
INFO - 00:50:16: collected 6981 word types from a corpus of 58152 raw words and 2684 sentences
INFO - 00:50:16: Creating a fresh vocabulary
INFO - 00:50:16: Word2Vec lifecycle event {'msg': 'effective_min_count=5 retains 1750 unique words (25.07% of original 6981, drops 5231)', 'datetime': '2026-01-12T00:50:16.903242', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'prepare_vocab'}
INFO - 00:50:16: Word2Vec lifecycle event {'msg': 'effective_min_count=5 leaves 49335 word corpus (84.84% of original 58152, drops 8817)', 'datetime': '2026-01-12T00:50:16.903242', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'prepare_vocab'}
INFO - 00:50:16: deleting the raw counts dictionary of 6981 items
INFO - 00:50:16: sample=0.001 downsamples 51 most-common words
INFO - 00:50:16: Word2Vec lifecycle event {'msg': 'downsampling leaves estimated 35935.33721568072 word corpus (72.8%% of prior 49335)', 'datetime': '2026-01-12T00:50:16.950120', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'prepare_vocab'}
INFO - 00:50:17: estimated required memory for 1750 words and 100 dimensions: 2275000 bytes
INFO - 00:50:17: resetting layer weights
INFO - 00:50:17: Word2Vec lifecycle event {'update': False, 'trim_rule': 'None', 'datetime': '2026-01-12T00:50:17.040154', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'build_vocab'}
Czas budowania słownika: 0.22 s.
t = time()
model.train(sntcs, total_examples=model.corpus_count, epochs=30) #model.epochs
print(f"Czas treningu modelu: {round((time() - t), 2)} s.")
INFO - 00:50:17: Word2Vec lifecycle event {'msg': 'training model with 19 workers on 1750 vocabulary and 100 features, using sg=0 hs=0 sample=0.001 negative=5 window=5 shrink_windows=True', 'datetime': '2026-01-12T00:50:17.063557', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'train'}
INFO - 00:50:17: EPOCH 0: training on 58152 raw words (35958 effective words) took 0.1s, 415213 effective words/s
INFO - 00:50:17: EPOCH 1: training on 58152 raw words (35961 effective words) took 0.1s, 454344 effective words/s
INFO - 00:50:17: EPOCH 2: training on 58152 raw words (35833 effective words) took 0.1s, 404018 effective words/s
INFO - 00:50:17: EPOCH 3: training on 58152 raw words (35940 effective words) took 0.1s, 429807 effective words/s
INFO - 00:50:17: EPOCH 4: training on 58152 raw words (35808 effective words) took 0.1s, 420503 effective words/s
INFO - 00:50:17: EPOCH 5: training on 58152 raw words (35923 effective words) took 0.1s, 413109 effective words/s
INFO - 00:50:17: EPOCH 6: training on 58152 raw words (35948 effective words) took 0.1s, 417363 effective words/s
INFO - 00:50:18: EPOCH 7: training on 58152 raw words (35947 effective words) took 0.1s, 402008 effective words/s
INFO - 00:50:18: EPOCH 8: training on 58152 raw words (35802 effective words) took 0.1s, 409144 effective words/s
INFO - 00:50:18: EPOCH 9: training on 58152 raw words (35904 effective words) took 0.1s, 320176 effective words/s
INFO - 00:50:18: EPOCH 10: training on 58152 raw words (35981 effective words) took 0.1s, 390369 effective words/s
INFO - 00:50:18: EPOCH 11: training on 58152 raw words (36014 effective words) took 0.1s, 327746 effective words/s
INFO - 00:50:18: EPOCH 12: training on 58152 raw words (36022 effective words) took 0.1s, 427600 effective words/s
INFO - 00:50:18: EPOCH 13: training on 58152 raw words (35946 effective words) took 0.1s, 318451 effective words/s
INFO - 00:50:18: EPOCH 14: training on 58152 raw words (35909 effective words) took 0.1s, 674244 effective words/s
INFO - 00:50:18: EPOCH 15: training on 58152 raw words (36015 effective words) took 0.0s, 820793 effective words/s
INFO - 00:50:18: EPOCH 16: training on 58152 raw words (35924 effective words) took 0.0s, 1197543 effective words/s
INFO - 00:50:19: EPOCH 17: training on 58152 raw words (35920 effective words) took 0.0s, 1362273 effective words/s
INFO - 00:50:19: EPOCH 18: training on 58152 raw words (35918 effective words) took 0.0s, 1232212 effective words/s
INFO - 00:50:19: EPOCH 19: training on 58152 raw words (35822 effective words) took 0.0s, 1253574 effective words/s
INFO - 00:50:19: EPOCH 20: training on 58152 raw words (35988 effective words) took 0.0s, 1311277 effective words/s
INFO - 00:50:19: EPOCH 21: training on 58152 raw words (35967 effective words) took 0.0s, 1380325 effective words/s
INFO - 00:50:19: EPOCH 22: training on 58152 raw words (35972 effective words) took 0.0s, 1456958 effective words/s
INFO - 00:50:19: EPOCH 23: training on 58152 raw words (36020 effective words) took 0.0s, 1461839 effective words/s
INFO - 00:50:19: EPOCH 24: training on 58152 raw words (35983 effective words) took 0.0s, 1375371 effective words/s
INFO - 00:50:19: EPOCH 25: training on 58152 raw words (35889 effective words) took 0.0s, 1427622 effective words/s
INFO - 00:50:19: EPOCH 26: training on 58152 raw words (35857 effective words) took 0.0s, 1352242 effective words/s
INFO - 00:50:19: EPOCH 27: training on 58152 raw words (35895 effective words) took 0.0s, 1341032 effective words/s
INFO - 00:50:19: EPOCH 28: training on 58152 raw words (35953 effective words) took 0.0s, 1426531 effective words/s
INFO - 00:50:19: EPOCH 29: training on 58152 raw words (35932 effective words) took 0.0s, 1266411 effective words/s
INFO - 00:50:19: Word2Vec lifecycle event {'msg': 'training on 1744560 raw words (1077951 effective words) took 2.4s, 456065 effective words/s', 'datetime': '2026-01-12T00:50:19.430119', 'gensim': '4.3.3', 'python': '3.12.3 | packaged by conda-forge | (main, Apr 15 2024, 18:20:11) [MSC v.1938 64 bit (AMD64)]', 'platform': 'Windows-11-10.0.22631-SP0', 'event': 'train'}
Czas treningu modelu: 2.37 s.
model.wv.most_similar('sydney')
[('north', 0.9069498181343079),
('hobart', 0.8889608979225159),
('yacht', 0.8846085667610168),
('western', 0.8742423057556152),
('coast', 0.8608307838439941),
('spencer', 0.8305367827415466),
('queensland', 0.8202462792396545),
('tasmania', 0.8196939826011658),
('perth', 0.8184189796447754),
('lower', 0.8093999028205872)]
# PCA
pca = PCA(n_components=3)
X = pca.fit_transform(model.wv.get_normed_vectors())
y = model.wv.index_to_key
print(X.shape)
print(len(y))
(1750, 3)
1750
# graph 3d projection in Plotly
X_subset = X[100:300]
y_subset = y[100:300]
df = pd.DataFrame(X_subset, columns=['x', 'y', 'z'])
fig = px.scatter_3d(df, x='x', y='y', z='z', color=y_subset)
fig.show()
Możemy zauważyć, że np. słowa national oraz state są blisko siebie na rzucie w przestrzeni trzywymiarowej.
# similarity between national and state
model.wv.similarity('national', 'state')
0.8060473
GloVe#
Dokumentacja: https://nlp.stanford.edu/projects/glove/
Fine-tuning jest procesem dalszego trenowania modelu na mniejszych, bardziej specyficznych zbiorach danych. Fine-tuning modelu może okazać się dobrym pomysłem, kiedy nasz zbiór danych jest zbyt mały, aby model wytrenować tylko na tych danych, lub kiedy słowa z danego zbioru danych nie występują we wstępnie wytrenowanym już modelu, ponieważ dotyczą np. specjalistycznego słownictwa.
Jak zrobić fine-tuning na wytrenowanym modelu GloVe można przeczytać w tym artykule: https://towardsdatascience.com/fine-tune-glove-embeddings-using-mittens-89b5f3fe4c39
Word2Vec (CBOW i Skip-gram) uczy się reprezentacji słów, predykując słowa w kontekście lub kontekst na podstawie słów, korzystając z lokalnych statystyk (sąsiedztwa słów) w korpusie. GloVe (Global Vectors) bazuje na globalnych statystykach współwystępowania słów, budując macierz współwystępowania (co-occurence matrix) i optymalizując wektory, by oddawały te relacje w skali całego korpusu.
Macierz współwystępowania, oznaczana jako \(X\), jest tworzona na podstawie danego korpusu tekstowego oraz słownika. Wartość \(X_{ij}\) oznacza liczę razy, kiedy słowo \(j\) występuje w oknie kontekstowym słowa \(i\). Sumując wszystkie elementy w wierszu \(i\), uzyskujemy łączną liczbę słów, które pojawiają się w kontekście danego słowa, co zapisujemy jako \(X_i = \sum_k X_{ik}\). W związku z tym, prawdopodobieństwo wystąpienia słowa \(j\) w kontekście słowa \(i\) można obliczyć za pomocą następującego wzoru:
Rozmiar okna to maksymalne przesunięcie kontekstu, w obrębie którego słowa muszą być przewidywane. Na przykład, gdy rozmiar okna wynosi 2, model będzie przewidywał słowa w kontekście lokalizacji (t-2), (t-1), (t+1) oraz (t+2). Wybór rozmiaru okna ma istotny wpływ na jakość wyuczonych wektorów słów. Mniejszy rozmiar okna sprzyja lepszemu zrozumieniu syntaktycznych ról słów, podczas gdy większy rozmiar okna pozwala modelowi na uchwycenie szerszego kontekstu semantycznego.
rozmiar okna = 1
Źródło: https://jramkiss.github.io/2019/08/21/word-embeddings/
Biblioteka transformers#
Biblioteka Transformers to narzędzie stworzone przez firmę Hugging Face, które umożliwia łatwy dostęp do zaawansowanych modeli opartych na architekturze transformerów, zwłaszcza w dziedzinach przetwarzania języka naturalnego (NLP). Wykorzystuje modele, takie jak BERT, GPT-2, RoBERTa, T5, i wiele innych, które osiągają świetne wyniki w zadaniach takich jak tłumaczenie tekstów, generowanie tekstów, analiza sentymentu, odpowiadanie na pytania czy klasyfikacja tekstów. Modele dostępne w bibliotece są wytrenowane na dużych zbiorach danych, ale można je dostosować do specyficznych zadań lub danych poprzez fine-tuning.
Czym są transformery?
Model transformer po raz pierwszy został przedstawiony w artykule Attention is All You Need w 2017 roku (https://arxiv.org/abs/1706.03762) i zrewolucjonizował NLP. Zasada działania opiera się na mechanizmie uwagi (attention), który pozwala modelowi skupiać się na istotnych fragmentach sekwencji wejściowej. Dzięki temu transformery potrafią lepiej uchwycić zależności między słowami w zdaniu, niezależnie od ich odległości.
Dokumentacja: https://huggingface.co/docs/transformers/index
Poniższy model: https://huggingface.co/BAAI/bge-base-en-v1.5
# Sentences we want sentence embeddings for
sentences = ["Lubię NLP", "Lubię czytać", "W lato jest ciepło"]
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
Sentence embeddings: tensor([[-0.0140, 0.0274, 0.0051, ..., -0.0541, -0.0308, -0.0188],
[ 0.0023, -0.0426, -0.0051, ..., -0.0573, 0.0074, 0.0162],
[ 0.0357, -0.0118, -0.0433, ..., -0.0244, 0.0009, 0.0369]])
print(f"Wymiar wektora: {len(sentence_embeddings[0])}")
Wymiar wektora: 1024