Inżynieria cech#
Feature Engineering polega na przekształcaniu surowych danych w cechy użyteczne w procesie modelowania.
Tworzenie zmiennych predykcyjnych zawsze powinno opierać się przede wszystkim na zrozumieniu danych i wiedzy biznesowej związanej z danym problemem. Istnieje jednak kilka standardowych technik, które można stosować do tworzenia cech w większości problemów, można tu wyróżnić:
przekształcanie zmiennych kategorycznych
zmienne na podstawie cech z daty
zmienne powstałe przez przesunięcie w czasie
transformacje zmiennych numerycznych
zmienne interakcji
Feature Engineering stanowi jeden z ważniejszych etapów w procesie budowy uczenia maszynowego, dlatego należy mu poświęcić dużo uwagi. Często można uzyskać znacznie lepsze wyniki mając prosty model oparty na cechach predykcyjnych dobrze oddających naturę badanego zjawiska niż budując wyrafinowany model w oparciu o zbyt wąski zbiór zmiennych.
Tworzenie przykładowych zbiorów danych#
Zaprezentujemy tutaj 2 przykładowe zbiory danych o różnym charakterze oraz przykłady zmiennych predykcyjnych, które można wygenerować na ich podstawie
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def generateIceCreamSalesData(month_coef=10000, week_coef=1000, day_coef=100, random_coef =10000):
dates = pd.date_range(start="2018-01-01", end="2020-12-31", freq ="D")
df = pd.DataFrame(dates, columns=["SalesDate"])
df["Month"] = df.SalesDate.dt.month
df["Week"] = df.SalesDate.dt.isocalendar().week.astype(int)
df["WeekDay"] = df.SalesDate.dt.dayofweek+1
df["IceCreamSales"] = (-1*np.power(df.Month-6,2)+np.power(6,2))*month_coef + (-1*np.power(df.Week-27,2)+np.power(27,2))*week_coef +df.WeekDay*day_coef +random_coef * np.random.randint(low =1,high =10, size=len(df))
return df.loc[:,["SalesDate","IceCreamSales"]]
IceCream_df = generateIceCreamSalesData()
IceCream_df.head()
| SalesDate | IceCreamSales | |
|---|---|---|
| 0 | 2018-01-01 | 213100 |
| 1 | 2018-01-02 | 173200 |
| 2 | 2018-01-03 | 243300 |
| 3 | 2018-01-04 | 233400 |
| 4 | 2018-01-05 | 253500 |
def generate_used_cars_data(len_df =1000):
conditions ={"very_bad":1,"bad":2,"medium":3,"good":4,"very_good":5}
brands =["Fiat","Renault","VW", "Seat", "Skoda","Toyota", "Audi","BMW","Mercedes", "Bugatti"]
standard_brands = ["Fiat","Renault","VW", "Seat", "Skoda","Toyota"]
premium_brands = ["Audi","BMW","Mercedes"]
luxury_brands = ["Bugatti"]
dict_data ={"condition":np.random.choice(list(conditions.keys()),size=len_df, p = [0.05, 0.15, 0.3, 0.3,0.2 ]),
"brand":np.random.choice(brands,size=len_df, p=[0.1]*10 ),
"year_manufactured":np.random.randint(1950,2020,size =len_df)
}
df = pd.DataFrame(dict_data)
df["age"] =2026- df.year_manufactured
df["mileage"] = df.age *np.random.randint(100,10000, len_df)+np.random.randint(100,10000, len_df)
df["selling_price"] = 100000*df["brand"].isin(standard_brands)+300000*df["brand"].isin(premium_brands)+600000*df["brand"].isin(luxury_brands)
df["selling_price"] /= np.log1p(df.age)+np.log1p(df.mileage)
df["condition_num"] = df.condition.map(lambda x:conditions[x])
df["selling_price"] *= np.log1p(df["condition_num"])
df.loc[(df["brand"].isin(luxury_brands))&(df.year_manufactured<=1970)&(df["condition_num"]>3),"selling_price"] *=\
np.log1p(df.loc[(df["brand"].isin(luxury_brands))&(df.year_manufactured<=1970)&(df["condition_num"]>3),"age"])
df["selling_price"] = np.round(df["selling_price"])
return df.loc[:,["selling_price","condition","mileage","brand","year_manufactured"]]
UsedCars_df =generate_used_cars_data()
UsedCars_df.head()
| selling_price | condition | mileage | brand | year_manufactured | |
|---|---|---|---|---|---|
| 0 | 9341.0 | good | 467749 | Renault | 1962 |
| 1 | 10750.0 | very_good | 275003 | Toyota | 1964 |
| 2 | 28133.0 | good | 516663 | Audi | 1972 |
| 3 | 8000.0 | medium | 459747 | VW | 1954 |
| 4 | 28021.0 | good | 515964 | BMW | 1968 |
Cechy tworzone na podstawie danych czasowych#
Pierwszy zbiór danych nazwany tutaj IceCream_df de facto ma charakter szeregu czasowego i patrząc na poniższy wykres mógłby być z powodzeniem przewidywany dedykowanymi metodami do predykcji szeregów czasowych, jednak dla celów pokazania tworzenia zmiennych na podstawie danych o charakterze czasowym potraktujemy to zagadnienie jako problem regresyjny, w którym naszą zmienną celu będzie IceCreamSales.
IceCream_df.set_index("SalesDate").plot(figsize=(15,9), title="IceCream Sales")
<Axes: title={'center': 'IceCream Sales'}, xlabel='SalesDate'>
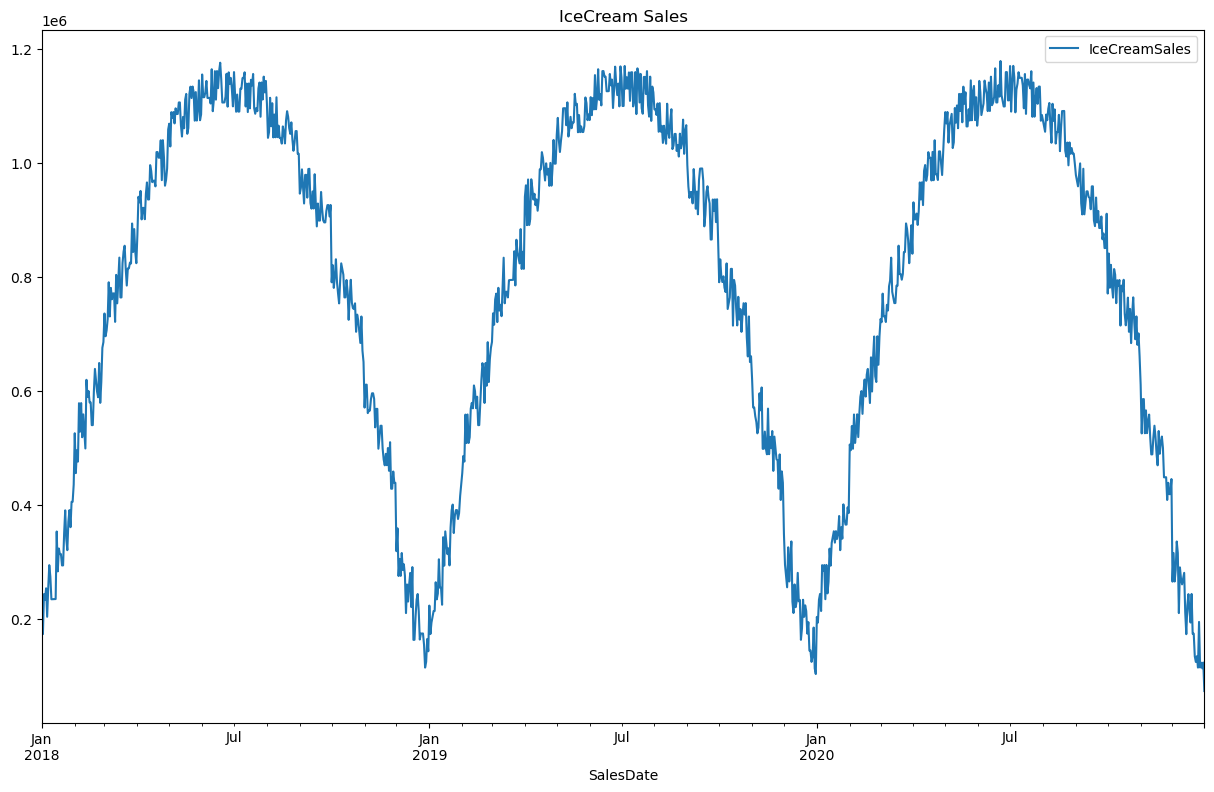
Wyraźnie widać tutaj, że sprzedaż lodów ma silnie sezonowy charakter, stąd cechy wyciągnięte z daty powinny znacznie ułatwić dobrą predykcję. Funkcję generującą takie cechy zaprezentowano poniżej:
def extract_date_features(df, date_column):
df_temp = df.copy()
df_temp[date_column + 'Quarter'] = df_temp[date_column].dt.quarter
df_temp[date_column + 'Month'] = df_temp[date_column].dt.month
df_temp[date_column + 'Week'] = df_temp[date_column].dt.isocalendar().week.astype(int)
# poniżej zwracany rozkład to 0-6, dodajemy 1 aby przejsc na bardziej intuicyjne wartości 1-7
df_temp[date_column + 'WeekDay'] = df_temp[date_column].dt.dayofweek + 1
df_temp[date_column + 'YearDay'] = df_temp[date_column].dt.day_of_year
df_temp[date_column + 'isWeekend'] = np.where(df_temp[date_column + 'WeekDay']>5,1,0)
return df_temp
IceCream_df_extended = extract_date_features(IceCream_df,"SalesDate")
IceCream_df_extended.head()
| SalesDate | IceCreamSales | SalesDateQuarter | SalesDateMonth | SalesDateWeek | SalesDateWeekDay | SalesDateYearDay | SalesDateisWeekend | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 | 213100 | 1 | 1 | 1 | 1 | 1 | 0 |
| 1 | 2018-01-02 | 173200 | 1 | 1 | 1 | 2 | 2 | 0 |
| 2 | 2018-01-03 | 243300 | 1 | 1 | 1 | 3 | 3 | 0 |
| 3 | 2018-01-04 | 233400 | 1 | 1 | 1 | 4 | 4 | 0 |
| 4 | 2018-01-05 | 253500 | 1 | 1 | 1 | 5 | 5 | 0 |
Cechy powstałe przez przesunięcie w czasie#
Analizując wykres można zaobserwować, że sprzedaż lodów nie jest liniowo zależna od zmiennych takich jak numer kwartału, numer miesiąca czy numer tygodnia, aby uzyskać lepsze wyniki warto zbudować cechy w oparciu o przesunięte w czasie wartości zmiennej celu.
Przy korzystaniu ze zmiennych przesuniętych w czasie, w szczególności opartych o wcześniejsze wartości zmiennej celu należy zawsze wziąć pod uwagę jakie dane będziemy mieli dostępne na moment predykcji, inaczej możemy popełnić jeden z najczęstszych błędów czyli data leakage. Przy założeniu, że mamy przewidywać sprzedaż lodów np na rok do przodu wykorzystanie sprzedaży lodów z dnia poprzedniego stanowi data leakage, ponieważ ta informacja nie będzie dostępna na moment predykcji w tej samej formie. Moglibyśmy natomiast uwzględnić sprzedaż lodów sprzed roku, jako, że ta informacja będzie dostępna w tej samej formie.
Tutaj dla uproszczenia zakładamy chwilowo, że horyzont predykcji to tylko 1 dzień do przodu, co pozwoli zaprezentować większy zakres zmiennych przesuniętych w czasie.
def get_shifted_target_values(df, lag_values, date_column, target_column):
df_temp = df.copy()
df_temp =df_temp.sort_values(by=date_column)
for lag in lag_values:
df_temp[target_column +"_lagged_" + str(lag)] = df_temp[target_column].shift(lag)
return df_temp
Uwzględniając, że przewidujemy z horyzontem czasowym tylko na dzień w przód, pierwszym kandydatem na wartość przesunięcia jest 1 dzień, jako, że w danych o charakterze szeregu czasowego podobieństwo kolejnych obserwacji będzie siłą rzeczy relatywnie wysokie. Z analizy wykresu można łatwo wywnioskować, że wartośc przesunięcia 365 dni również będzie miała dużą siłę predykcyjną. Ponadto można tutaj wypróbować 7 dni co powinno być przydatne w przypadku tygodniowej sezonowości danych
IceCream_df_extended = get_shifted_target_values(IceCream_df_extended, [1,7,365], "SalesDate","IceCreamSales")
IceCream_df_extended
| SalesDate | IceCreamSales | SalesDateQuarter | SalesDateMonth | SalesDateWeek | SalesDateWeekDay | SalesDateYearDay | SalesDateisWeekend | IceCreamSales_lagged_1 | IceCreamSales_lagged_7 | IceCreamSales_lagged_365 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2018-01-01 | 213100 | 1 | 1 | 1 | 1 | 1 | 0 | NaN | NaN | NaN |
| 1 | 2018-01-02 | 173200 | 1 | 1 | 1 | 2 | 2 | 0 | 213100.0 | NaN | NaN |
| 2 | 2018-01-03 | 243300 | 1 | 1 | 1 | 3 | 3 | 0 | 173200.0 | NaN | NaN |
| 3 | 2018-01-04 | 233400 | 1 | 1 | 1 | 4 | 4 | 0 | 243300.0 | NaN | NaN |
| 4 | 2018-01-05 | 253500 | 1 | 1 | 1 | 5 | 5 | 0 | 233400.0 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1091 | 2020-12-27 | 114700 | 4 | 12 | 52 | 7 | 362 | 1 | 194600.0 | 173700.0 | 134600.0 |
| 1092 | 2020-12-28 | 123100 | 4 | 12 | 53 | 1 | 363 | 0 | 114700.0 | 174100.0 | 184700.0 |
| 1093 | 2020-12-29 | 113200 | 4 | 12 | 53 | 2 | 364 | 0 | 123100.0 | 134200.0 | 113100.0 |
| 1094 | 2020-12-30 | 123300 | 4 | 12 | 53 | 3 | 365 | 0 | 113200.0 | 124300.0 | 103200.0 |
| 1095 | 2020-12-31 | 73400 | 4 | 12 | 53 | 4 | 366 | 0 | 123300.0 | 134400.0 | 203300.0 |
1096 rows × 11 columns
Widzimy, że początek zbioru danych zawiera teraz wartości puste, ze względu na fakt, że dla wartości z roku 2018 nie istniały obserwacje cofnięte o rok. Do pokazywania liczby niepustych wartości w ramce danych przydatna jest funkcja info z biblioteki pandas.
IceCream_df_extended.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1096 entries, 0 to 1095
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 SalesDate 1096 non-null datetime64[ns]
1 IceCreamSales 1096 non-null int32
2 SalesDateQuarter 1096 non-null int32
3 SalesDateMonth 1096 non-null int32
4 SalesDateWeek 1096 non-null int32
5 SalesDateWeekDay 1096 non-null int32
6 SalesDateYearDay 1096 non-null int32
7 SalesDateisWeekend 1096 non-null int32
8 IceCreamSales_lagged_1 1095 non-null float64
9 IceCreamSales_lagged_7 1089 non-null float64
10 IceCreamSales_lagged_365 731 non-null float64
dtypes: datetime64[ns](1), float64(3), int32(7)
memory usage: 64.3 KB
oczywiście wartości puste należy potem w jakiś sposób obsłużyć, poprzez ich usunięcie lub imputację
Tworząc zmienne oparte o cechy przesunięte w czasie warto mieć na uwadze, że dane historyczne mogą zawierać wartości odstające. Dlatego zamiast brać wprost wartość sprzed np. 365 dni można rozważyć wygładzenie wartości stosując medianę z 5 dniowego okna, którego środek stanowi wartość sprzed 365 dni.
Cechy kategoryczne i ich transformacje#
Dla zilustrowania transformacji na zmiennych kategorycznych posłużymy się drugim z przygotowanych zbiorów danych, gdzie chcemy przewidzieć cenę sprzedaży używanego samochodu.
UsedCars_df.head()
| selling_price | condition | mileage | brand | year_manufactured | |
|---|---|---|---|---|---|
| 0 | 9341.0 | good | 467749 | Renault | 1962 |
| 1 | 10750.0 | very_good | 275003 | Toyota | 1964 |
| 2 | 28133.0 | good | 516663 | Audi | 1972 |
| 3 | 8000.0 | medium | 459747 | VW | 1954 |
| 4 | 28021.0 | good | 515964 | BMW | 1968 |
Jak widzimy występują tutaj 2 cechy kategoryczne condition oraz brand, na podstawie których zaprezentujemy które transformacje danych najlepiej zastosować w którym przypadku. Aby umożliwić wykorzystanie tych cech w predykcji niezbędne jest odpowiednie ich przekształcenie w wartości numeryczne.
UsedCars_df.condition.unique()
array(['good', 'very_good', 'medium', 'bad', 'very_bad'], dtype=object)
patrząc na atrybuty zmiennej condition widzimy, że ma ona charakter porządkowy - jesteśmy w stanie łatwo ustalić naturalną kolejność jej atrybutów. Stanowi ona zatem dobrego kandydata do zastosowania kodowania porządkowego.
kodowania porządkowe (ang. Ordinal encoding) - reprezentacja każdego atrybutu kodowanej zmiennej jako kolejnej liczby naturalnej.
Poniżej zaprezentujemy kodowanie porządkowe z użyciem transformera OrdinalEncoder, najpierw jednak podzielimy nasze dane na zbiór treningowy i testowy, aby lepiej odwzorować to, że dane treningowe są oddzielone od danych produkcyjnych, na których model będzie potem stosowany.
from sklearn.preprocessing import OrdinalEncoder
from sklearn.model_selection import train_test_split
Tutaj dla uproszczenia stosujemy podział tylko na zbiór treningowy i testowy, generalnie najlepszą praktyką jest wydzielenie osobnego zbioru testowego reprezentującego zdolność modelu do generalizacji na nowych, niewidzianych wcześniej danych i dobór najlepszego zestawu parametrów i transformacji stosując walidację krzyżową (ang. cross-validation) na zbiorze treningowym.
X_train, X_test = train_test_split(UsedCars_df, test_size =0.25, random_state=42)
Następnie tworzymy obiekt klasy OrdinalEncoder, określamy tutaj porządek cechy atrybutów cechy, którą chcemy przetransformować, inaczej mogą one zostać po prostu posortowane alfabetycznie co najczęściej nie będzie odpowiadało ich znaczeniu biznesowemu.
oe = OrdinalEncoder(categories =[['very_bad', 'bad', 'medium', 'good', 'very_good']],
handle_unknown ='use_encoded_value', unknown_value=np.nan)
Kodując atrybuty należy mieć świadomość, że na nowych danych mogą pojawić się niewidziane wcześniej wartości, które należy w jakiś sposób obsłużyć. Domyślnym zachowaniem OrdinalEncoder w takiej sytuacji jest zwrócenie wyjątku, tutaj skorzystaliśmy z przypisania mu ustalonej wartości, gdzie wybraliśmy przypisanie wartości pustej. Następnie taką wartość można zastąpić np. dominantą ze zbioru treningowego, lub przypisać jej wartość neutralną, którą tutaj byłoby 2 odpowiadające kategorii medium.
Zdecydowanie najlepszym sposobem użycia wszystkich transformerów jest skorzystanie z pipeline, co zostanie zaprezentowane potem. Tutaj zaprezentujemy najprostsze wykorzystanie polegające na skorzystaniu z metod fit i transform. OrdinalEncoder stosujemy tylko do przekształcenia jednej cechy, gdyby było inaczej moglibyśmy wykonać fit na całym zbiorze treningowym a następnie przetransformować zbiory treningowy i testowy.
oe.fit(X_train.condition.values.reshape(-1, 1))
X_train["condition_transformed"] = oe.transform(X_train.condition.values.reshape(-1, 1))
X_test["condition_transformed"] = oe.transform(X_test.condition.values.reshape(-1, 1))
Jeśli nie korzystamy z pipeline należy zwrócić szczególną uwagę żeby metody fit używać tylko na zbiorze treningowym a następnie mając już “nauczony” transformer stosować metodę transform na pozostałych zbiorach. Inaczej może dojść do przecieku informacji ze zbioru testowego.
Możemy jeszcze sprawdzić czy przypisanie atrybutów na zbiorach treningowym i testowym jest prawidłowe, a następnie pozbyć się pierwotnej kolumny, wartości pierwotne mogą być łatwo odzyskane z przetransformowanych danych stosując metodę inverse_transform.
X_train[["condition","condition_transformed"]].drop_duplicates().sort_values(by="condition_transformed")
| condition | condition_transformed | |
|---|---|---|
| 323 | very_bad | 0.0 |
| 991 | bad | 1.0 |
| 82 | medium | 2.0 |
| 398 | good | 3.0 |
| 894 | very_good | 4.0 |
X_test[["condition","condition_transformed"]].drop_duplicates().sort_values(by="condition_transformed")
| condition | condition_transformed | |
|---|---|---|
| 312 | very_bad | 0.0 |
| 513 | bad | 1.0 |
| 740 | medium | 2.0 |
| 678 | good | 3.0 |
| 521 | very_good | 4.0 |
X_train.drop(["condition"], axis=1, inplace=True)
X_test.drop(["condition"], axis=1, inplace=True)
X_train.head()
| selling_price | mileage | brand | year_manufactured | condition_transformed | |
|---|---|---|---|---|---|
| 82 | 9742.0 | 43278 | VW | 1992 | 2.0 |
| 991 | 6848.0 | 125388 | Fiat | 1953 | 1.0 |
| 789 | 20344.0 | 293403 | BMW | 1990 | 1.0 |
| 894 | 11233.0 | 264488 | VW | 1995 | 4.0 |
| 398 | 35125.0 | 27437 | Mercedes | 1993 | 3.0 |
Widzimy, że do zakodowania pozostała nam jeszcze cecha - brand, w odróżnieniu od poprzednio rozważanej cechy tutaj nie ma oczywistego naturalnego porządku, dlatego należy tutaj zastosować inne podejście.
kodowania 1 z n (ang. One-hot encoding) - reprezentacja każdego atrybutu kodowanej zmiennej jako osobnej zmiennej binarnej, gdzie występowanie rozważanego atrybutu dla danej obserwacji oznaczane jest jako 1, a wszystkie pozostałe atrybuty oznaczane są jako 0.
Kodowanie 1 z n stanowi jeden z najczęściej używanych i najbardziej intuicyjnych sposobów kodowania, jednak jego główną wadą jest zwiększanie wymiarowości danych, co zaraz zaprezentujemy.
Najpierw pokażemy jak posługiwać się transformerem OneHotEncoder.
from sklearn.preprocessing import OneHotEncoder
Tworzymy obiekt klasy OneHotEncoder, podobnie jak w przypadku poprzedniego transformera, tu także domyślnym sposobem obsługi nieznanych atrybutów jest zwracanie wyjątku, my wybieramy handle_unknown=”ignore” co sprawi, że nieznane atrybuty reprezentowane będą po prostu jako 0 we wszystkich zakodowanych kolumnach.
Natomiast ustawienie sparse_output=False sprawia, że zwracane dane będą typu np.array zamiast domyślnego sparse matrix.
ohe = OneHotEncoder(handle_unknown="ignore", sparse_output=False)
Należy zwrócić uwagę, że we wszystkich transformerach z biblioteki sklearn stosowane jest to samo API, w związku z tym tutaj analogicznie jak w poprzednim przypadku możemy skorzystać z metod fit i transform.
ohe.fit(X_train.brand.values.reshape(-1, 1))
brand_transformed_train = ohe.transform(X_train.brand.values.reshape(-1, 1))
brand_transformed_test = ohe.transform(X_test.brand.values.reshape(-1, 1))
print(f"rozmiar zakodowanej kolumny brand na danych treningowych to: {brand_transformed_train.shape}")
print(f"rozmiar zakodowanej kolumny brand na danych testowych to: {brand_transformed_test.shape}")
print(brand_transformed_train)
rozmiar zakodowanej kolumny brand na danych treningowych to: (750, 10)
rozmiar zakodowanej kolumny brand na danych testowych to: (250, 10)
[[0. 0. 0. ... 0. 0. 1.]
[0. 0. 0. ... 0. 0. 0.]
[0. 1. 0. ... 0. 0. 0.]
...
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]]
Jak widzimy kolumna brand reprezentowana jest teraz jako array gdzie każdy atrybut ze zbioru treningowego zaprezentowany jest w osobnej kolumnie binarnej. Można to sprawdzić zliczając liczbę unikalnych atrybutów tej kolumny na zbiorze treningowym.
X_train.brand.nunique()
10
Kolejność atrybutów odpowiadających kolumnom wynikowego arraya można zobaczyć korzystając z atrybutu categories_
ohe.categories_
[array(['Audi', 'BMW', 'Bugatti', 'Fiat', 'Mercedes', 'Renault', 'Seat',
'Skoda', 'Toyota', 'VW'], dtype=object)]
Całą transformację wraz z dodaniem przetransformowanej zmiennej do zbioru treningowego można zrealizować za pomocą prostej funkcji.
def OneHotEncode(X_train, X_test, encoded_column_name, **encoder_kwargs):
ohe = OneHotEncoder(**encoder_kwargs)
ohe.fit(X_train[encoded_column_name].values.reshape(-1, 1))
transformed_train = ohe.transform(X_train[encoded_column_name].values.reshape(-1, 1))
transformed_test = ohe.transform(X_test[encoded_column_name].values.reshape(-1, 1))
column_names = [encoded_column_name +"_"+category for category in list(ohe.categories_[0]) ]
df_transformed_train = pd.DataFrame(transformed_train, columns = column_names)
df_transformed_test = pd.DataFrame(transformed_test, columns = column_names)
df_out_train = X_train.reset_index(drop=True).drop([encoded_column_name], axis=1)
df_out_test = X_test.reset_index(drop=True).drop([encoded_column_name], axis=1)
df_out_train = pd.concat([df_out_train, df_transformed_train],axis=1)
df_out_test = pd.concat([df_out_test, df_transformed_test],axis=1)
return df_out_train, df_out_test
Powyższa funkcja zwraca zbiór treningowy i testowy po dodaniu odpowiednio nazwanych kolumn powstałych po transformacji obiektem OneHotEncoder i usunięciu pierwotnej zmiennej. Argumenty do OneHotEncoder przekazywane są z pomocą **encoder_kwargs
X_train_ohe, X_test_ohe = OneHotEncode(X_train, X_test, "brand", handle_unknown="ignore",sparse_output=False)
X_train_ohe.head()
| selling_price | mileage | year_manufactured | condition_transformed | brand_Audi | brand_BMW | brand_Bugatti | brand_Fiat | brand_Mercedes | brand_Renault | brand_Seat | brand_Skoda | brand_Toyota | brand_VW | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 9742.0 | 43278 | 1992 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 6848.0 | 125388 | 1953 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 20344.0 | 293403 | 1990 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 11233.0 | 264488 | 1995 | 4.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 4 | 35125.0 | 27437 | 1993 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
Alternatywnie zamiast OneHotEncoder można wykorzystać funkcję get_dummies z biblioteki pandas, która jest nieco prostsza w użyciu, jednak OneHotEncoder jest lepiej dostosowany do obsługi niewidzianych wartości, a ponadto znacznie łatwiej go zastosować w ramach pipeline.
Jak widzimy nawet przy tak niskiej liczbie atrybutów wymiarowość naszych danych znacznie wzrosła. W prawdziwych zastosowaniach możemy się spotkać ze zbiorami danych mającymi wiele zmiennych kategorycznych o dziesiątkach lub setkach unikalnych atrybutów, więc metodę OneHotEncoder zaleca się stosować tylko tam, gdzie atrybuty są niezbyt liczne, w pozostałych sytuacjach lepiej skorzystać z kodowania zmienną celu
kodowanie zmienną celu (ang. Target encoding) - reprezentacja każdego atrybutu kodowanej zmiennej jako estymata średniej wartości zmiennej celu na danych treningowych.
Kodowanie zmienną celu stanowi jedną z najbardziej uniwersalnych metod kodowania zmiennych kategorycznych, nie wymaga naturalnego porządku w danych jak kodowanie porządkowe i nie zwiększa wymiarowości danych jak kodowanie 1 z n.
Istnieje wiele różnych sposobów kodowania zmiennej celu, my tutaj posłużymy się metodą James-Stein Encoder dostępną w bibliotece category_encoders.
Formuła na zakodowaną wartość k-tego atrybutu kodowanej zmiennej: $\( X_{k} = (1-B) *Avg(Y_{k}) +B*Avg(Y) \)$
gdzie:
\(X_{k}\) - wartość przypisana k-temu atrybutowi kodowanej zmiennej kategorycznej
\(Avg(Y_{k})\) - średnia wartości zmiennej celu dla k-tego atrybutu zmiennej kategorycznej
\(Avg(Y)\) - globalna średnia zmiennej celu na zbiorze treningowym
\(B\) -waga globalnej średniej, wyliczona według formuły: $\( B = \frac{Var(Y_{k})}{Var(Y) + Var(Y_{k})} \)$ gdzie:
\(Var(Y_{k})\) - wariancja zmiennej celu dla k-tego atrybutu zmiennej kategorycznej
\(Var(Y)\) - wariancja zmiennej celu dla całego zbioru treningowego
Importujemy potrzebną klasę.
from category_encoders.james_stein import JamesSteinEncoder
Tworzymy obiekt klasy JamesSteinEncoder, wybierając kolumnę brand do przekształcenia. Domyślnie przekształcone zostaną wszystkie kolumny kategoryczne.
jse = JamesSteinEncoder(cols=["brand"])
Tak jak w transformerach z biblioteki sklearn także tutaj posługujemy się metodami fit i transform, jednak jako, że jest to kodowanie zmienną celu niezbędne jest jej podanie do metody fit, dlatego najpierw wydzielimy zmienną celu.
y_train = X_train.selling_price
y_test = X_test.selling_price
X_train = X_train.drop("selling_price", axis=1)
X_test = X_test.drop("selling_price", axis=1)
jse.fit(X_train,y_train)
X_train_jse = jse.transform(X_train)
X_test_jse = jse.transform(X_test)
X_train_jse.head()
| mileage | brand | year_manufactured | condition_transformed | |
|---|---|---|---|---|
| 82 | 43278 | 9629.353191 | 1992 | 2.0 |
| 991 | 125388 | 9870.552327 | 1953 | 1.0 |
| 789 | 293403 | 29622.078340 | 1990 | 1.0 |
| 894 | 264488 | 9629.353191 | 1995 | 4.0 |
| 398 | 27437 | 27918.584205 | 1993 | 3.0 |
Jak widzimy zmienna brand została teraz zastąpiona estymatami średniej wartości zmiennej celu w zależności od brandu.
Łączenie atrybutów cech kategorycznych#
Oprócz standardowych metod transformacji zmiennych kategorycznych opisanych w poprzedniej sekcji można też stosować różne przekształcenia polegające na łączeniu pierwotnych atrybutów w podgrupy. Takie łączenie może być oparte na podobieństwie atrybutów pod katęm statystycznym np. zbliżony poziom średniej wartości zmiennej celu lub, co bardziej zalecane - na wiedzy domenowej.
Tutaj zaprezentujemy prosty przykład łączenia atrybutów oparty na wiedzy domenowej - załóżmy, że znamy podział wszystkich marek samochodów ze zmiennej brand na 3 relatywnie jednolite podgrupy - marki podstawowe, marki premium i marki luksusowe. Na tej podstawie stworzymy nową zmienną korzystając z prostej funkcji:
def brand_binning(brand):
result = "standard"
standard_brands = ["Fiat", "Renault", "VW", "Seat", "Skoda", "Toyota"]
premium_brands = ["Audi", "BMW", "Mercedes"]
luxury_brands = ["Bugatti"]
if brand in luxury_brands:
result = "luxury"
elif brand in premium_brands:
result = "premium"
return result
X_train["brand_binned"] = X_train["brand"].map(lambda x:brand_binning(x))
X_test["brand_binned"] = X_test["brand"].map(lambda x:brand_binning(x))
X_train.head()
| mileage | brand | year_manufactured | condition_transformed | brand_binned | |
|---|---|---|---|---|---|
| 82 | 43278 | VW | 1992 | 2.0 | standard |
| 991 | 125388 | Fiat | 1953 | 1.0 | standard |
| 789 | 293403 | BMW | 1990 | 1.0 | premium |
| 894 | 264488 | VW | 1995 | 4.0 | standard |
| 398 | 27437 | Mercedes | 1993 | 3.0 | premium |
Możemy też sprawdzić jak wygląda unikalne przypisanie pomiędzy pierwotną, a zgrupowaną zmienną:
X_train[["brand","brand_binned"]].drop_duplicates().sort_values(by="brand_binned")
| brand | brand_binned | |
|---|---|---|
| 868 | Bugatti | luxury |
| 789 | BMW | premium |
| 398 | Mercedes | premium |
| 323 | Audi | premium |
| 82 | VW | standard |
| 991 | Fiat | standard |
| 916 | Skoda | standard |
| 731 | Toyota | standard |
| 266 | Renault | standard |
| 631 | Seat | standard |
jak widzimy przypisanie zostało przeprowadzone poprawnie, nowa zmienna niesie mniej informacji niż zmienna pierwotna, dlatego zastąpienie nią pierwotnej zmiennej może być pomocne jeśli mamy problem z przeuczeniem modelu. Oczywiście tak powstałą zmienną należy potem jeszcze przetransformować zgodnie z wytycznymi z poprzedniej sekcji.
Cechy oparte na wiedzy domenowej oraz cechy interakcji#
Zaprezentowane powyżej grupowanie marek polegało na przekształceniu zmiennej kategorycznej w oparciu o wiedzę domenową. Tutaj pokażemy przykłady zastosowania wiedzy domenowej na zmiennych numerycznych i interakcji cech numerycznych i katgorycznych.
Przykładem prostej cechy opartej na wiedzy domenowej może być wiek samochodu w momencie sprzedaży. Nie mamy tutaj informacji o dacie transakcji, dlatego można dla ułatwienia założyć, że wszystkie transakcje odbyły się w bieżącym roku.
X_train["age"] = 2025 - X_train["year_manufactured"]
X_test["age"] = 2025 - X_test["year_manufactured"]
X_train
| mileage | brand | year_manufactured | condition_transformed | brand_binned | age | |
|---|---|---|---|---|---|---|
| 82 | 43278 | VW | 1992 | 2.0 | standard | 33 |
| 991 | 125388 | Fiat | 1953 | 1.0 | standard | 72 |
| 789 | 293403 | BMW | 1990 | 1.0 | premium | 35 |
| 894 | 264488 | VW | 1995 | 4.0 | standard | 30 |
| 398 | 27437 | Mercedes | 1993 | 3.0 | premium | 32 |
| ... | ... | ... | ... | ... | ... | ... |
| 106 | 42788 | Renault | 2019 | 4.0 | standard | 6 |
| 270 | 30630 | VW | 1999 | 4.0 | standard | 26 |
| 860 | 63121 | Audi | 1952 | 3.0 | premium | 73 |
| 435 | 135219 | Renault | 1987 | 1.0 | standard | 38 |
| 102 | 46463 | Mercedes | 1953 | 2.0 | premium | 72 |
750 rows × 6 columns
Zmienne interakcji można wygenerować stosując np. iloczyny poszczególnych zmiennych numerycznych, tutaj wydaje się to nie być najlepszy pomysł, ponieważ intuicyjnie czujemy, że np mnożenie przebiegu * rok produkcji nie będzie zbyt dobrą cechą predykcyjną. Można natomiast wyliczyć np. średni roczny przebieg dzieląc przebieg przez dodany powyżej wiek samochodu.
X_train["avg_yearly_mileage"] = np.round(X_train["mileage"] / X_train["age"])
X_test["avg_yearly_mileage"] = np.round(X_test["mileage"] / X_test["age"])
X_train
| mileage | brand | year_manufactured | condition_transformed | brand_binned | age | avg_yearly_mileage | |
|---|---|---|---|---|---|---|---|
| 82 | 43278 | VW | 1992 | 2.0 | standard | 33 | 1311.0 |
| 991 | 125388 | Fiat | 1953 | 1.0 | standard | 72 | 1742.0 |
| 789 | 293403 | BMW | 1990 | 1.0 | premium | 35 | 8383.0 |
| 894 | 264488 | VW | 1995 | 4.0 | standard | 30 | 8816.0 |
| 398 | 27437 | Mercedes | 1993 | 3.0 | premium | 32 | 857.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 106 | 42788 | Renault | 2019 | 4.0 | standard | 6 | 7131.0 |
| 270 | 30630 | VW | 1999 | 4.0 | standard | 26 | 1178.0 |
| 860 | 63121 | Audi | 1952 | 3.0 | premium | 73 | 865.0 |
| 435 | 135219 | Renault | 1987 | 1.0 | standard | 38 | 3558.0 |
| 102 | 46463 | Mercedes | 1953 | 2.0 | premium | 72 | 645.0 |
750 rows × 7 columns
Innym przykładem zmiennej opartej stricte na wiedzy domenowej łączącej ze sobą informacje ze zmiennych numerycznych i kategorycznych mogła by być informacja o klasycznych modelach. Załóżmy, że modele luksusowych marek wyprodukowane przed 1970 rokiem są modelami klasycznymi i jeśli ich stan jest co najmniej dobry to ich cena jest znacznie wyższa niż by to wynikało z wieku auta, gdzie normalnie spodziewamy się ujemnej relacji z ceną sprzedaży.
X_train.loc[(X_train.brand_binned=="luxury")&(X_train.year_manufactured<=1970)&(X_train.condition_transformed>2.0),"is_classic"]=1
X_train["is_classic"] = X_train["is_classic"].fillna(0)
X_test.loc[(X_test.brand_binned=="luxury")&(X_test.year_manufactured<=1970)&(X_test.condition_transformed>2.0),"is_classic"]=1
X_test["is_classic"] = X_test["is_classic"].fillna(0)
X_train["is_classic"].value_counts()
is_classic
0.0 734
1.0 16
Name: count, dtype: int64
Takie przypadki są stosunkowo rzadkie, ale tego typu zmienna może pomóc w dokładniejszym przewidzeniu tych obserwacji.
Cechy oparte na transformacji zmiennych numerycznych#
Dość powszechnie spotykaną praktyką jest stosowanie nieliniowych transformacji zmiennych numerycznych, co zazwyczaj sprzyja uzyskaniu lepszej jakości predykcji ze względu na fakt, że modele najlepiej radzą sobie gdy rozkłady zmiennych są zbliżone do rozkładu normalnego.
Często spotykaną jest po prostu logarytmowanie zmiennych numerycznych, tutaj natomiast posłużymy się gotowym transformerem z biblioteki sklearn, a mianowicie PowerTransformer
from sklearn.preprocessing import PowerTransformer
Zanim dokonamy transformacji sprawdźmy jak wyglądają rozkłady zmiennych numerycznych, ograniczymy się tutaj do przebiegu, wieku i średniego przebiegu.
num_columns = ["mileage", "age","avg_yearly_mileage"]
X_train[num_columns].hist(figsize=(15,9), bins=30)
array([[<Axes: title={'center': 'mileage'}>,
<Axes: title={'center': 'age'}>],
[<Axes: title={'center': 'avg_yearly_mileage'}>, <Axes: >]],
dtype=object)
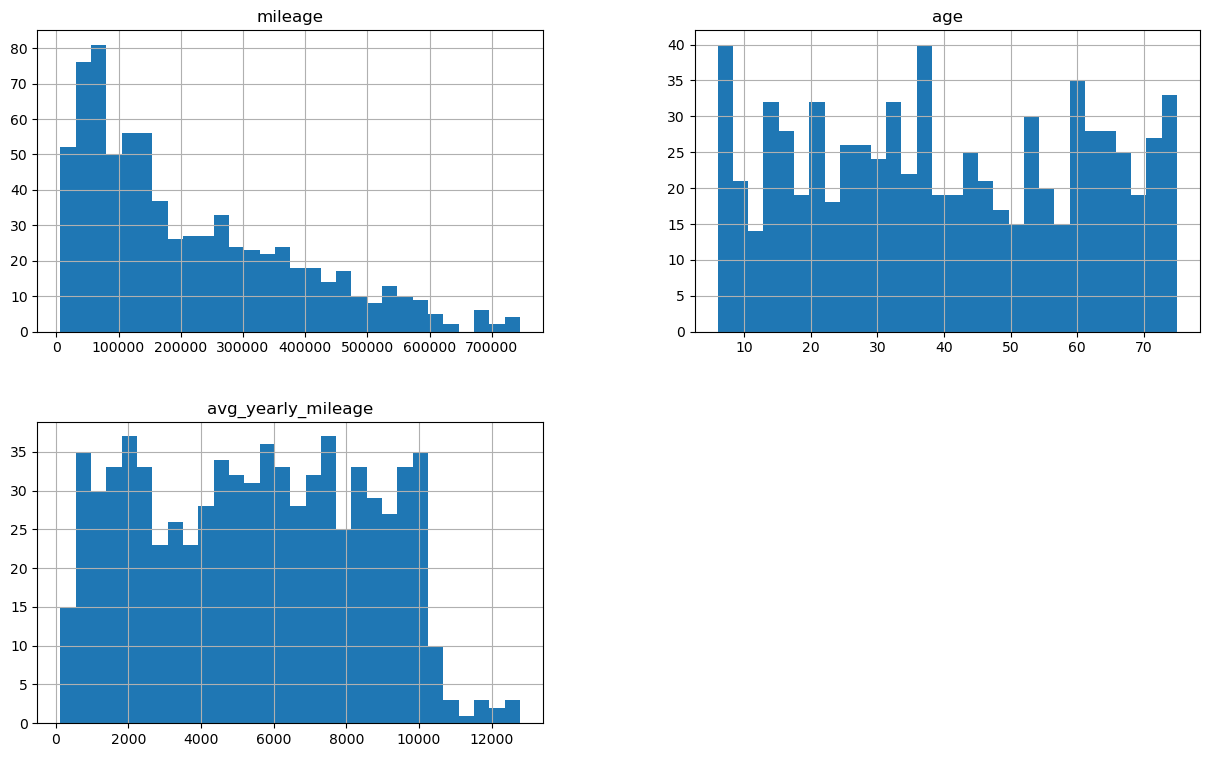
Można tu zaobserwować, że rozkład przebiegu jest silnie skośny, pozostałe 2 zmienne mają rozkład zbliżony do jednostajnego.
pt=PowerTransformer(standardize=False)
Tworzymy obiekt klasy PowerTransformer, korzystamy tutaj z domyślnej transformacji Yeo-Johnson, zmieniamy natomiast ustawienie o sprowadzeniu do rozkładu o średniej równej 0 i odchyleniu standardowym równym 1, które domyślnie jest ustawione na True.
Domyślna transformacja czyli metoda Yeo-Johnsona może być stosowana niezależnie od znaku transformowanych zmiennych, natomiast alternatywna transformacja Box-Cox wymaga ściśle dodatnich zmiennych na wejściu.
pt.fit(X_train[num_columns])
X_train_num_transformed = pd.DataFrame(pt.transform(X_train[num_columns]), columns = num_columns)
X_test_num_transformed = pd.DataFrame(pt.transform(X_test[num_columns]), columns = num_columns)
Analogicznie jak przy poprzednio stosowanych transformerach korzystamy tutaj z metod fit i transform, a następnie konwertujemy wynik na ramkę danych.
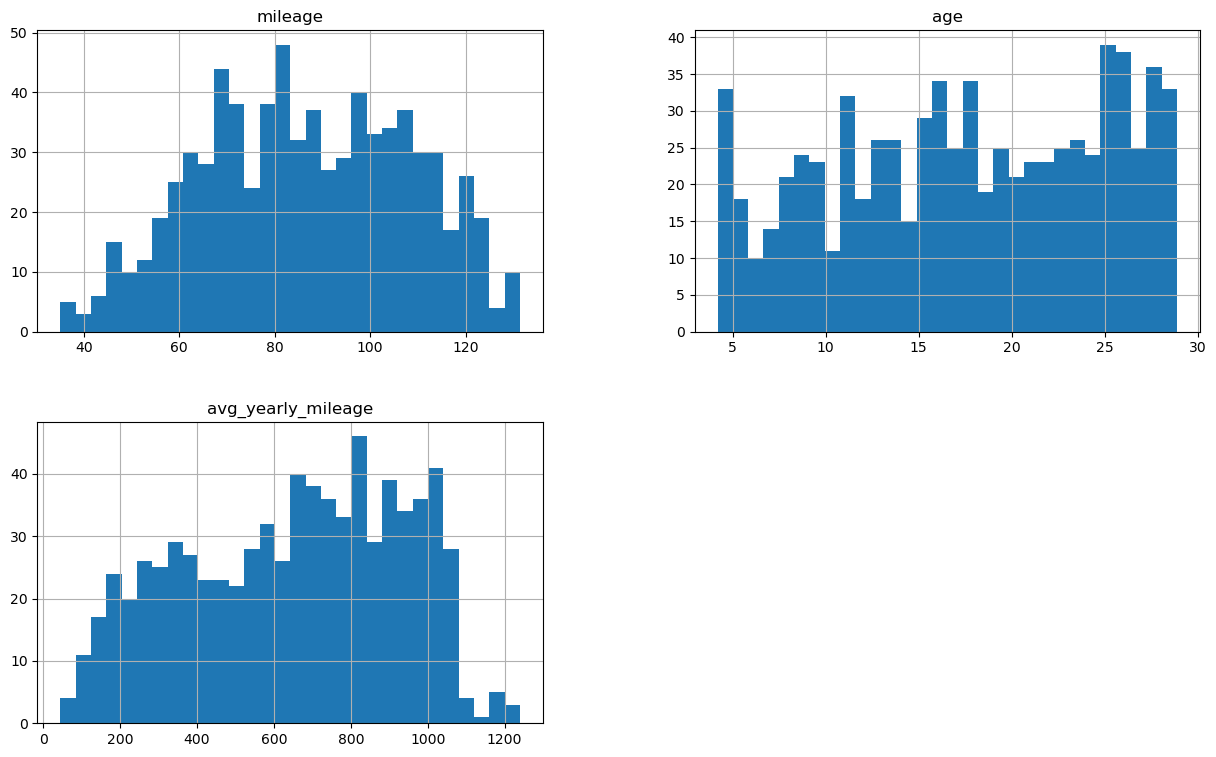
Przeanalizujmy jak mocno zmieniły się rozkłady poszczególnych zmiennych:
X_train_num_transformed.hist(figsize=(15,9), bins=30)
array([[<Axes: title={'center': 'mileage'}>,
<Axes: title={'center': 'age'}>],
[<Axes: title={'center': 'avg_yearly_mileage'}>, <Axes: >]],
dtype=object)
X_test_num_transformed.hist(figsize=(15,9), bins=30)
array([[<Axes: title={'center': 'mileage'}>,
<Axes: title={'center': 'age'}>],
[<Axes: title={'center': 'avg_yearly_mileage'}>, <Axes: >]],
dtype=object)
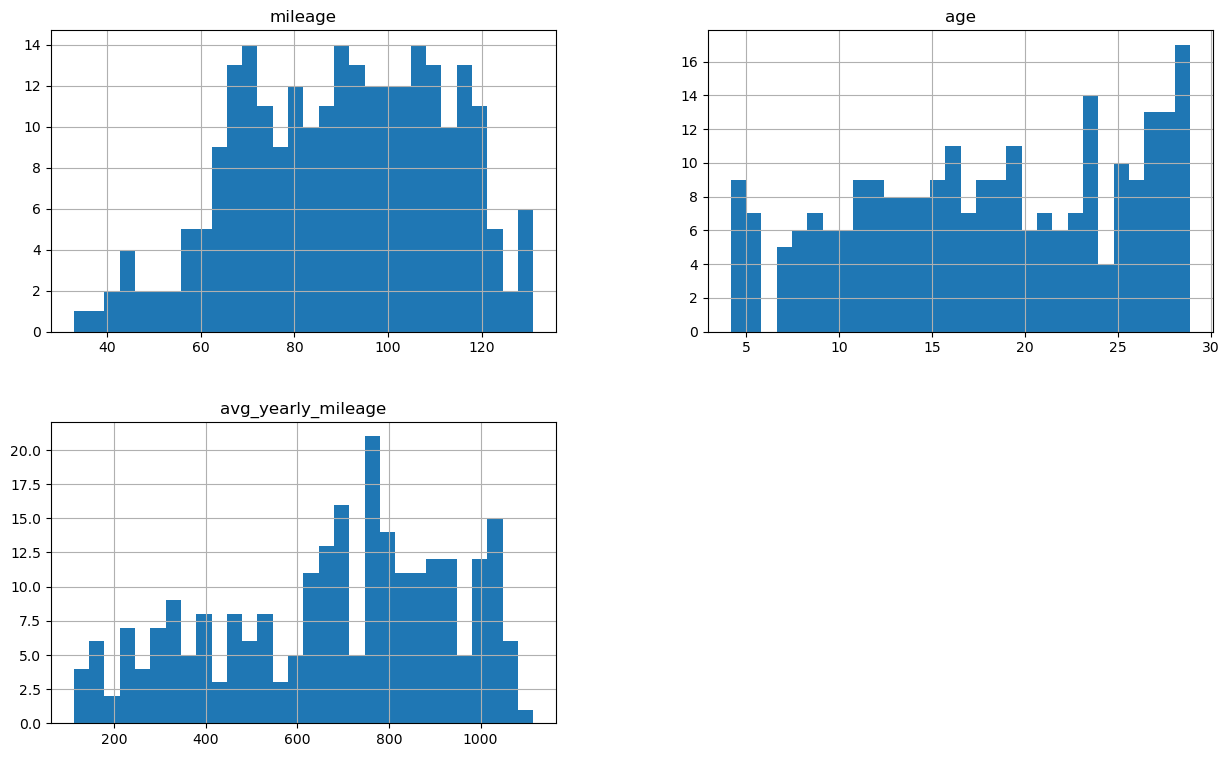
Zmienna mileage na zbiorze treningowym z silnie skośnej nabrała cech rozkładu normalnego, pozostałe przypadki nie wyglądają jednak na rozkład normalny.
Wypróbujmy inny sposób modyfikacji rozkładu - QuantileTransformer
from sklearn.preprocessing import QuantileTransformer
tworzymy obiekt klasy QuantileTransformer, zamiast bazowego rozkładu jednostajnego wybierając rozkład normalny
qt = QuantileTransformer(n_quantiles=100, output_distribution="normal")
qt.fit(X_train[num_columns])
X_train_num_transformed = pd.DataFrame(qt.transform(X_train[num_columns]), columns =num_columns)
X_test_num_transformed = pd.DataFrame(qt.transform(X_test[num_columns]), columns =num_columns)
X_train_num_transformed.hist(figsize=(15,9), bins=30)
array([[<Axes: title={'center': 'mileage'}>,
<Axes: title={'center': 'age'}>],
[<Axes: title={'center': 'avg_yearly_mileage'}>, <Axes: >]],
dtype=object)
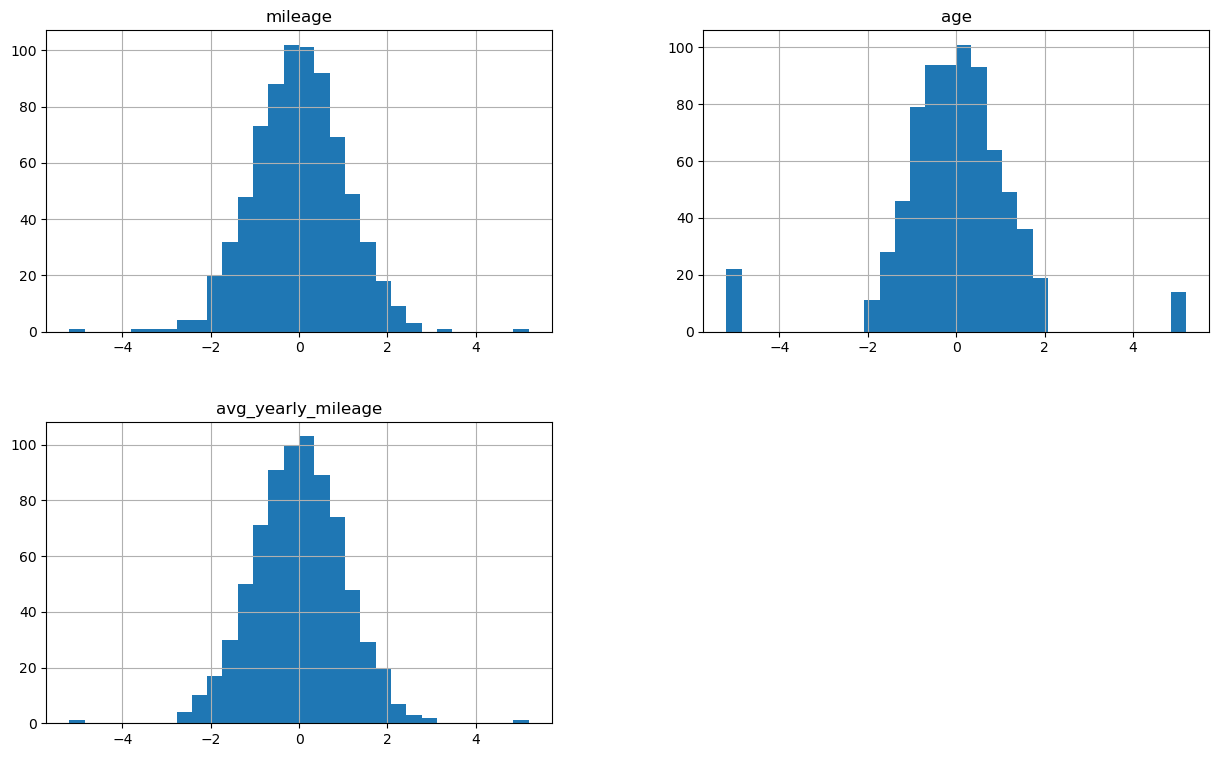
X_test_num_transformed.hist(figsize=(15,9), bins=30)
array([[<Axes: title={'center': 'mileage'}>,
<Axes: title={'center': 'age'}>],
[<Axes: title={'center': 'avg_yearly_mileage'}>, <Axes: >]],
dtype=object)
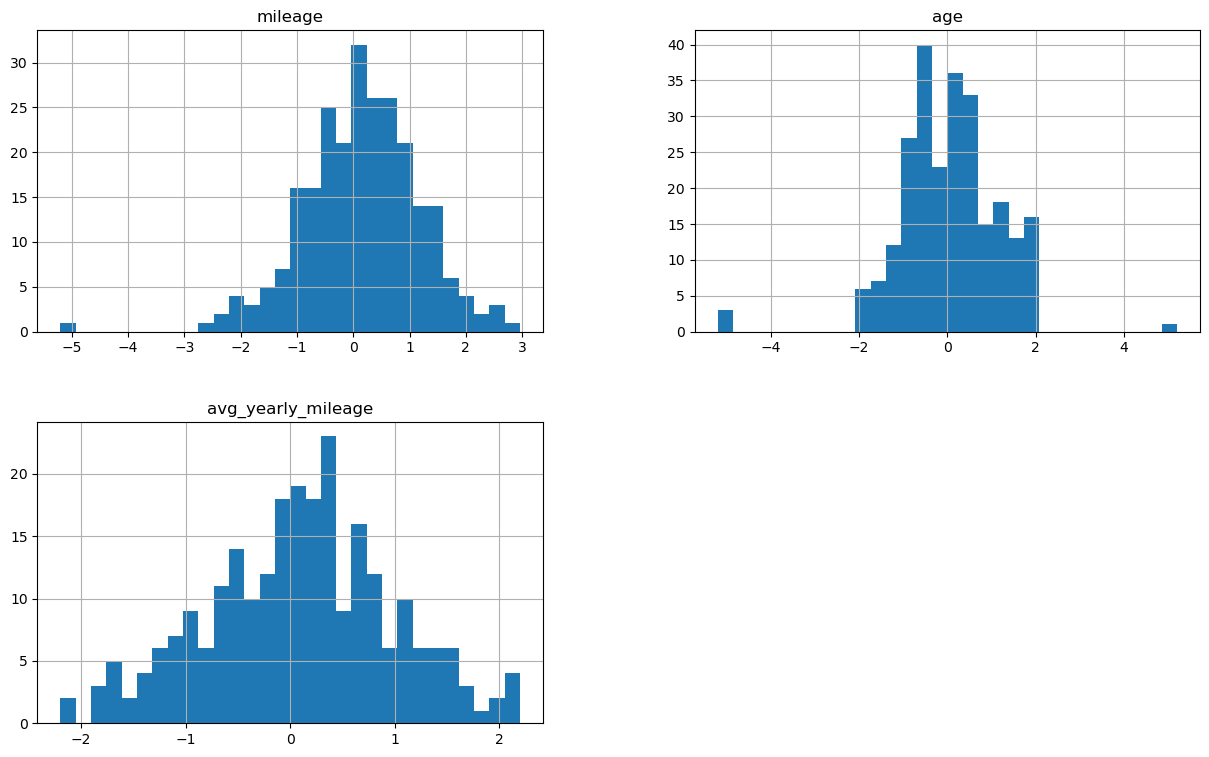
Jak widzimy rozkłady są teraz zupełnie inne, na zbiorze treningowym bardzo zbliżone do rozkładu normalnego, jednak na zbiorze testowym juz dość znacznie się różnią, co może wynikać po części z niewielkiego rozmiaru próby.
To jaki dokładnie zestaw transformacji ostatecznie wybrać powinno wynikać przede wszystkim z obserwacji ustalonej wcześniej metryki jakości modelu.
Łączenie zmiennych numerycznych w przedziały#
Podobnie jak w przypadku zmiennych kategorycznych, zmienne numeryczne również można przekształcać grupując razem pewne ich wartości. Proces taki nazywamy kubełkowaniem.
Kubełkowanie (ang. binning) polega na łączeniu wartości zmiennych numerycznych w przedziały, ma to na celu zmniejszenie możliwości przeuczenia modelu.
Wybór takich przedziałów może występować zarówno na podstawie cech rozkładu zmiennych (np wartości kwartyli) jak i wiedzy domenowej, tutaj zaprezentujemy obie możliwości.
Do podziału wg statystyk pozycyjnych z rozkładu wykorzystamy funkcję qcut z biblioteki pandas.
X_train["mileage_binned_4"] = pd.qcut(X_train["mileage"], q=4)
X_train["mileage_binned_10"] = pd.qcut(X_train["mileage"], q=10)
X_train[["mileage", "mileage_binned_4", "mileage_binned_10"]]
| mileage | mileage_binned_4 | mileage_binned_10 | |
|---|---|---|---|
| 82 | 43278 | (6691.999, 75146.5] | (39749.3, 64024.8] |
| 991 | 125388 | (75146.5, 158637.0] | (123185.8, 158637.0] |
| 789 | 293403 | (158637.0, 320447.5] | (280306.8, 360364.2] |
| 894 | 264488 | (158637.0, 320447.5] | (219253.2, 280306.8] |
| 398 | 27437 | (6691.999, 75146.5] | (6691.999, 39749.3] |
| ... | ... | ... | ... |
| 106 | 42788 | (6691.999, 75146.5] | (39749.3, 64024.8] |
| 270 | 30630 | (6691.999, 75146.5] | (6691.999, 39749.3] |
| 860 | 63121 | (6691.999, 75146.5] | (39749.3, 64024.8] |
| 435 | 135219 | (75146.5, 158637.0] | (123185.8, 158637.0] |
| 102 | 46463 | (6691.999, 75146.5] | (39749.3, 64024.8] |
750 rows × 3 columns
Stworzyliśmy tutaj 2 nowe cechy na zbiorze treningowym w oparciu o kwartyle i decyle rozkładu zmiennej mileage. Jak widzimy poszczególnym wartościom przypisane zostały wartości przedziałów do których one wpadają w danym podziale na kubełki.
Jeśli chcemy samodzielnie określić etykiety przedziałów można posłużyć się parametrem labels
X_train["mileage_binned_4"] = pd.qcut(X_train["mileage"], q=4, labels=np.arange(1,5))
X_train["mileage_binned_10"] = pd.qcut(X_train["mileage"], q=10, labels=np.arange(1,11))
X_train[["mileage","mileage_binned_4","mileage_binned_10"]]
| mileage | mileage_binned_4 | mileage_binned_10 | |
|---|---|---|---|
| 82 | 43278 | 1 | 2 |
| 991 | 125388 | 2 | 5 |
| 789 | 293403 | 3 | 8 |
| 894 | 264488 | 3 | 7 |
| 398 | 27437 | 1 | 1 |
| ... | ... | ... | ... |
| 106 | 42788 | 1 | 2 |
| 270 | 30630 | 1 | 1 |
| 860 | 63121 | 1 | 2 |
| 435 | 135219 | 2 | 5 |
| 102 | 46463 | 1 | 2 |
750 rows × 3 columns
Wszystkie przekształcenia wykorzystujące informacje o rozkładach cech należy implementować najpierw na zbiorze treningowym, a następnie w oparciu o rozkład ze zbioru treningowego - na zbiorze testowym. Inaczej wykorzystujemy informacje ze zbioru testowego i przestaje on być niezależny.
Tutaj możemy skorzystać z parametru retbins i dostać granice kubełków, a następnie w oparciu o te granice dokonać identycznego podziału na zbiorze testowym.
_, bins = pd.qcut(X_train["mileage"], q=4, retbins=True)
bins
array([ 6692. , 75146.5, 158637. , 320447.5, 744946. ])
Alternatywnym podejściem jest użycie funkcji cut z biblioteki pandas, która pozwala podzielić wartości zmiennej na zdefiniowaną liczbę przedziałów o identycznej szerokości lub przypisać je do zdefiniowanych samodzielnie przedziałów.
Załóżmy, że jeśli chodzi o wiek samochodu znaczenie mają przedziały do 3 lat, od 3 do 7, od 7 do 12, 12-25 oraz ponad 25. Możemy łatwo dokonać takiego przypisania przydzielając poszczególnym kubełkom odpowiednie nazwy:
X_train["age_binned"] = pd.cut(X_train["age"],[0,3,7,12,25,100], labels =["new","middle_age","old","very_old","extremely_old"] )
X_train[["age","age_binned"]]
| age | age_binned | |
|---|---|---|
| 82 | 33 | extremely_old |
| 991 | 72 | extremely_old |
| 789 | 35 | extremely_old |
| 894 | 30 | extremely_old |
| 398 | 32 | extremely_old |
| ... | ... | ... |
| 106 | 6 | middle_age |
| 270 | 26 | extremely_old |
| 860 | 73 | extremely_old |
| 435 | 38 | extremely_old |
| 102 | 72 | extremely_old |
750 rows × 2 columns
Normalizacja i Standaryzacja#
Załóżmy, że finalnie mamy zbiór danych złożony stricte ze zmiennych numerycznych:
X_train = X_train.loc[:,["mileage", "condition_transformed", "age", "avg_yearly_mileage", "is_classic"]]
X_test = X_test.loc[:,["mileage", "condition_transformed", "age", "avg_yearly_mileage", "is_classic"]]
X_train
| mileage | condition_transformed | age | avg_yearly_mileage | is_classic | |
|---|---|---|---|---|---|
| 82 | 43278 | 2.0 | 33 | 1311.0 | 0.0 |
| 991 | 125388 | 1.0 | 72 | 1742.0 | 0.0 |
| 789 | 293403 | 1.0 | 35 | 8383.0 | 0.0 |
| 894 | 264488 | 4.0 | 30 | 8816.0 | 0.0 |
| 398 | 27437 | 3.0 | 32 | 857.0 | 0.0 |
| ... | ... | ... | ... | ... | ... |
| 106 | 42788 | 4.0 | 6 | 7131.0 | 0.0 |
| 270 | 30630 | 4.0 | 26 | 1178.0 | 0.0 |
| 860 | 63121 | 3.0 | 73 | 865.0 | 0.0 |
| 435 | 135219 | 1.0 | 38 | 3558.0 | 0.0 |
| 102 | 46463 | 2.0 | 72 | 645.0 | 0.0 |
750 rows × 5 columns
Możemy łatwo zaobserwować, że zmienne znacznie różnią się pod względem średniej czy wariancji:
np.round(X_train.describe(), 2)
| mileage | condition_transformed | age | avg_yearly_mileage | is_classic | |
|---|---|---|---|---|---|
| count | 750.00 | 750.00 | 750.00 | 750.00 | 750.00 |
| mean | 212651.32 | 2.46 | 40.19 | 5475.97 | 0.02 |
| std | 168178.11 | 1.11 | 20.55 | 3020.22 | 0.14 |
| min | 6692.00 | 0.00 | 6.00 | 129.00 | 0.00 |
| 25% | 75146.50 | 2.00 | 23.00 | 2745.00 | 0.00 |
| 50% | 158637.00 | 3.00 | 39.00 | 5548.00 | 0.00 |
| 75% | 320447.50 | 3.00 | 59.00 | 8001.25 | 0.00 |
| max | 744946.00 | 4.00 | 75.00 | 12776.00 | 1.00 |
Niektóre metody modelowania są zależne od odległości bądź wariancji zmiennych, więc chcąc aby wpływ danej zmiennej na predykcje wynikał przede wszystkim z jej związku ze zmienną celu, a nie ze skali, powinniśmy zastosować normalizację lub standaryzację
zacznijmy od normalizacji, zrealizujemy ją za pomocą kolejnego transformera z biblioteki sklearn: MinMaxScaler
Normalizacja polega na przekształcaniu zmiennej do zakresu wartości <0,1> poprzez odjęcie minumum i podzielenie przez różnicę pomiędzy maksimum, a minimum z rozkładu.
from sklearn.preprocessing import MinMaxScaler
Tworzymy obiekt klasy MinMaxScaler korzystając z bazowych ustawień, możliwa jest zmiana docelowego zakresu wartości z bazowego <0,1> na dowolnie wybrany poprzez użycie parametru feature_range
mm = MinMaxScaler()
Metody są oczywiście analogiczne jak w poprzednich przypadkach, konwertujemy wyniki z powrotem na ramki danych aby łatwiej było je oglądać.
mm.fit(X_train)
X_train_mm_scaled = pd.DataFrame(mm.transform(X_train), columns=X_train.columns)
X_test_mm_scaled = pd.DataFrame(mm.transform(X_test), columns=X_test.columns)
np.round(X_train_mm_scaled.describe(),2)
| mileage | condition_transformed | age | avg_yearly_mileage | is_classic | |
|---|---|---|---|---|---|
| count | 750.00 | 750.00 | 750.00 | 750.00 | 750.00 |
| mean | 0.28 | 0.61 | 0.50 | 0.42 | 0.02 |
| std | 0.23 | 0.28 | 0.30 | 0.24 | 0.14 |
| min | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 25% | 0.09 | 0.50 | 0.25 | 0.21 | 0.00 |
| 50% | 0.21 | 0.75 | 0.48 | 0.43 | 0.00 |
| 75% | 0.42 | 0.75 | 0.77 | 0.62 | 0.00 |
| max | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
Jak widzimy wszystkie cechy zostały teraz przeniesione do tego samego zakresu wartości <0,1>, ale ich średnia i odchylenie standardowe nie są identyczne. Oczywiście nie mamy gwarancji, że na nowych danych nie pojawią się wartości spoza wykresu widzianego na zbiorze treningowym. Jeśli chcemy być pewni, że znormalizowane zmienne zachowają swój zakres wartości należy tworząc obiekt klasy MinMaxScaler ustawić parametr clip na True.
Nie zaleca się korzystania z MinMaxScaler dla zmiennych posiadających wartości odstające. Jeśli takie wartości nie zostaną wcześniej prawidłowo obsłużone, to większość “normalnych” wartości zmiennej będzie “upchana” w małym zakresie wartości co nie będzie sprzyjać jej wartości dla predykcji.
Zaprezentujemy teraz przykład standaryzacji z wykorzystaniem transformera StandardScaler z biblioteki sklearn.
Standaryzacja polega na przekształcaniu zmiennej do rozkładu o wartości oczekiwanej 0 i odchyleniu standardowym 1 poprzez odjęcie średniej i podzielenie przez odchylenie standardowe.
from sklearn.preprocessing import StandardScaler
Tworzymy obiekt klasy StandardScaler korzystając z bazowych ustawień.
ss = StandardScaler()
Metody rownież są analogiczne jak w poprzednich przypadkach, konwertujemy wyniki z powrotem na ramki danych aby łatwiej było je oglądać.
ss.fit(X_train)
X_train_ss_scaled = pd.DataFrame(ss.transform(X_train), columns=X_train.columns)
X_test_ss_scaled = pd.DataFrame(ss.transform(X_test), columns=X_test.columns)
np.round(X_train_ss_scaled.describe(),2)
| mileage | condition_transformed | age | avg_yearly_mileage | is_classic | |
|---|---|---|---|---|---|
| count | 750.00 | 750.00 | 750.00 | 750.00 | 750.00 |
| mean | 0.00 | -0.00 | -0.00 | -0.00 | 0.00 |
| std | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| min | -1.23 | -2.22 | -1.67 | -1.77 | -0.15 |
| 25% | -0.82 | -0.41 | -0.84 | -0.90 | -0.15 |
| 50% | -0.32 | 0.49 | -0.06 | 0.02 | -0.15 |
| 75% | 0.64 | 0.49 | 0.92 | 0.84 | -0.15 |
| max | 3.17 | 1.39 | 1.70 | 2.42 | 6.77 |
W przeciwieństwie do poprzedniego przekształcenia zmienne mają identyczną średnią i odchylenie standardowe, za to różnią sie zakresami wartości.
Jako że StandardScaler opiera się na użyciu średniej i odchylenia standardowego z transformowanej zmiennej, również nie jest on wolny od wpływu wartości odstających. Jeśli chcemy być pewni, że wartości odstające nie będą miały wpływu na skalę przekształconej zmiennej można skorzystać z klasy RobustScaler
Łączenie różnych transformacji w ramach pipeline#
Cofnijmy się teraz na chwilę do etapu generowania danych i zobaczmy jak można w łatwy i niezawodny sposób łączyć ze sobą różne transformacje z wykorzystaniem obiektów Pipeline oraz ColumnTransformer.
Pipeline jest to przepływ danych przez ułożone w kolejności moduły wykonujące ustalone transformacje, zazwyczaj ostatnim elementem jest model predykcyjny.
UsedCars_df =generate_used_cars_data()
X = UsedCars_df.drop("selling_price",axis=1)
y = UsedCars_df["selling_price"]
X["age"] = 2026 - X["year_manufactured"]
X.drop("year_manufactured", axis=1, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.25, random_state=42)
X_train
| condition | mileage | brand | age | |
|---|---|---|---|---|
| 82 | medium | 30887 | Mercedes | 13 |
| 991 | bad | 74735 | Renault | 7 |
| 789 | good | 359942 | Seat | 46 |
| 894 | medium | 167051 | Bugatti | 18 |
| 398 | bad | 131704 | Bugatti | 35 |
| ... | ... | ... | ... | ... |
| 106 | medium | 46755 | Seat | 14 |
| 270 | good | 95948 | BMW | 29 |
| 860 | very_good | 249796 | Fiat | 29 |
| 435 | medium | 459954 | Toyota | 56 |
| 102 | medium | 41051 | Mercedes | 11 |
750 rows × 4 columns
Zdefiniujmy teraz grupy zmiennych, które będziemy poddawać poszczególnym transformacjom.
columns_for_ordinal_encoding = ["condition"]
columns_for_target_encoding = ["brand"]
numerical_columns = ["age", "mileage"]
Następnie importujemy niezbędne klasy.
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
Definiujemy pipeline do przetwarzania poszczególnych grup kolumn, pipeline mogą zawierać wiele kroków, tutaj dla uproszczenia wykorzystamy jednoelementowe.
pipeline_oe = Pipeline(steps =[("OrdinalEncoder",
OrdinalEncoder(
categories = [['very_bad', 'bad', 'medium', 'good', 'very_good']],
handle_unknown = 'use_encoded_value', unknown_value=np.nan))])
pipeline_jse = Pipeline(steps=[("JamesSteinEncoder", JamesSteinEncoder())])
pipeline_num = Pipeline(steps=[("PowerTransformer", PowerTransformer(standardize=False))])
Następnie przypisujemy zmienne do poszczególnych transformacji, korzystając z obiektu ColumnTransformer.
column_transformer = ColumnTransformer(
transformers=[
('categorical_oe', pipeline_oe, columns_for_ordinal_encoding),
('categorical_jse', pipeline_jse, columns_for_target_encoding),
('numerical', pipeline_num, numerical_columns)
])
Sam ColumnTransformer również może być częścią pipeline, przykładowo możemy na koniec zastosować standaryzacje.
preprocessing_pipeline = Pipeline(steps = [
("column_transformer", column_transformer),
("scaler",StandardScaler())
])
Jeśli używamy pipeline bez modelu predykcyjnego na końcu to stosujemy te same metody co przy zwykłych transformerach.
preprocessing_pipeline.fit(X_train,y_train)
Pipeline(steps=[('column_transformer',
ColumnTransformer(transformers=[('categorical_oe',
Pipeline(steps=[('OrdinalEncoder',
OrdinalEncoder(categories=[['very_bad',
'bad',
'medium',
'good',
'very_good']],
handle_unknown='use_encoded_value',
unknown_value=nan))]),
['condition']),
('categorical_jse',
Pipeline(steps=[('JamesSteinEncoder',
JamesSteinEncoder())]),
['brand']),
('numerical',
Pipeline(steps=[('PowerTransformer',
PowerTransformer(standardize=False))]),
['age', 'mileage'])])),
('scaler', StandardScaler())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('column_transformer',
ColumnTransformer(transformers=[('categorical_oe',
Pipeline(steps=[('OrdinalEncoder',
OrdinalEncoder(categories=[['very_bad',
'bad',
'medium',
'good',
'very_good']],
handle_unknown='use_encoded_value',
unknown_value=nan))]),
['condition']),
('categorical_jse',
Pipeline(steps=[('JamesSteinEncoder',
JamesSteinEncoder())]),
['brand']),
('numerical',
Pipeline(steps=[('PowerTransformer',
PowerTransformer(standardize=False))]),
['age', 'mileage'])])),
('scaler', StandardScaler())])ColumnTransformer(transformers=[('categorical_oe',
Pipeline(steps=[('OrdinalEncoder',
OrdinalEncoder(categories=[['very_bad',
'bad',
'medium',
'good',
'very_good']],
handle_unknown='use_encoded_value',
unknown_value=nan))]),
['condition']),
('categorical_jse',
Pipeline(steps=[('JamesSteinEncoder',
JamesSteinEncoder())]),
['brand']),
('numerical',
Pipeline(steps=[('PowerTransformer',
PowerTransformer(standardize=False))]),
['age', 'mileage'])])['condition']
OrdinalEncoder(categories=[['very_bad', 'bad', 'medium', 'good', 'very_good']],
handle_unknown='use_encoded_value', unknown_value=nan)['brand']
JamesSteinEncoder()
['age', 'mileage']
PowerTransformer(standardize=False)
StandardScaler()
Po uruchomieniu metody fit widzimy wszystkie kroki całego pipeline.
X_train_transformed = preprocessing_pipeline.transform(X_train)
X_test_transformed = preprocessing_pipeline.transform(X_test)
print(f"rozmiar zbioru treningowego po transformacji: {X_train_transformed.shape}")
print(f"rozmiar zbioru testowego po transformacji: {X_test_transformed.shape}")
print(X_train_transformed)
rozmiar zbioru treningowego po transformacji: (750, 4)
rozmiar zbioru testowego po transformacji: (250, 4)
[[-0.3684896 0.8628722 -1.43447475 -1.37522187]
[-1.26578571 -0.7243835 -1.84885665 -0.70094894]
[ 0.52880651 -0.80133865 0.305422 1.00484543]
...
[ 1.42610261 -0.80626629 -0.52061678 0.53850626]
[-0.3684896 -0.80516424 0.75111605 1.34591852]
[-0.3684896 0.8628722 -1.56575144 -1.17619891]]
Jak widzimy zwrócony zbiór treningowy ma typ danych array, a jego wymiary odpowiadają tym przed transformacją, zgodność wymiarów zależy jednak od zastosowanych transformacji.
Jeśli pipeline jest zakończony modelem predykcyjnym jego metody są identyczne jak metody modelu, czyli korzystamy z fit i predict, tak jak w poniższym przykładzie.
from sklearn.linear_model import LinearRegression
final_pipeline = Pipeline(steps = [
("preprocessing", preprocessing_pipeline),
("model", LinearRegression())
])
Poniżej pokazujemy jak wytrenować pipeline w oparciu o zbiór treningowy, a następnie dokonać predykcji na zbiorze testowym.
final_pipeline.fit(X_train, y_train)
X_test_predicted = pd.Series(final_pipeline.predict(X_test),name="prediction")
X_test_predicted.head()
0 12231.876011
1 4089.555246
2 -44.372261
3 13263.196056
4 39668.160614
Name: prediction, dtype: float64
*Redukcja wymiarowości#
Czasem bardzo przydatną transformacją jest redukcja wymiarowości. Stosuje się ją, kiedy mamy zbyt wiele zmiennych objaśniających, redukcja wymiarowości w danych kategorycznych lub w celu zwizualizowania odpowiednich danych.
Z uwagi na to, że nasz zbiór ma mało danych to metody redukcji wymiarowości nie będą tu miały większego sensu. Warto jednak mieć na uwadzę, że istnieją i w niektórych specyficzynych sytuacjach mogą nam się przydać (np. na kolejnych zajęciach).
Do zmiennych numerycznych najprostszą metodą jest użycie PCA z pakietu sklearn.
from sklearn.decomposition import PCA
# Wybieramy tylko kolumny numeryczne
num_df = X_train.select_dtypes(include=["int32", "int64", "float"])
# Standaryzowanie danych (ważne przed PCA)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(num_df)
# Inicjalizacja i dopasowanie PCA
pca = PCA(n_components=1, random_state=42)
X_pca = pca.fit_transform(X_scaled)
Warto sprawdzić jak dobra jest nasza redukcja. Do tego sprawdzimy jak dużo wariancji wyjaśnia utworzona zmienna.
explained_variance_ratio = pca.explained_variance_ratio_
print("Explained variance ratio by component:")
print(explained_variance_ratio)
Explained variance ratio by component:
[0.81322877]
Przy użyciu metody MCA można zredukować wymiarowość danych kategorycznych
import prince
mca = prince.MCA(n_components=1, random_state=42)
mca_result = mca.fit_transform(X_train[['condition', 'brand']])
print(mca_result.head())
0
82 -0.093024
991 0.118299
789 -0.014156
894 0.069857
398 0.658080
Używając FAMD (Factor Analysis of Mixed Data) możemy zredukować wymiarowość mieszanych typów danych.
# Detekcja kolumn numerycznych i kategorycznych
num_cols = X_train.select_dtypes(include=["int32", "int64", "float"]).columns
cat_cols = X_train.select_dtypes(include=["object", "category"]).columns
# Konwersja numerycznych kolumn na float
X_train[num_cols] = X_train[num_cols].astype(float)
# Konwersja kategorycznych kolumn na typ 'category'
for col in cat_cols:
X_train[col] = X_train[col].astype("category")
# Zastosowanie FAMD (standaryzacja wewnętrzna jest wykonywana automatycznie)
famd = prince.FAMD(n_components=2, random_state=42)
famd_result = famd.fit_transform(X_train)
print(famd_result.head())
component 0 1
82 -1.462074 0.218207
991 -2.284276 -0.262719
789 1.150978 -0.152457
894 -0.884977 0.157945
398 -0.558227 0.792770
Istnieją jeszcze inne bardziej wyrafinowane metody - szczególnie przydatne w wizualizacji są t-SNE oraz UMAP. Zachęcam do samodzielnego zapozniania się z nimi.
Podsumowanie#
Powyżej zaprezentowaliśmy kilka różnych przykładów przekształcania surowych danych w cechy predykcyjne przydatne przy modelowaniu. Niektóre transformacje można z powodzeniem stosować przy pracy nad innymi problemami, inne należy raczej potraktować jako inspirację. Ważne aby prace nad Feature Engineering poprzedzone były dobrym zrozumieniem danych. Niezwykle ważne jest tutaj aby już na tym etapie stosować odpowiednią strategię walidacyjną, aby zapobiec korzystaniu z informacji ze zbioru testowego, inaczej nasze wyniki nie będą miarodajne.
Zadanie#
Opierając się na powyższych przykładach należy przeprowadzić Feature Engineering dla tabeli PG_01. Dane należy zczytać z bazy SQL bezpośrednio do ramki danych (podpowiedź na samej górze notatnika).
Transformacja powinna zawierać kilka elementów:
Należy utworzyć zmienną mówiącą o tym jak duża jest sprzedaż sztukowa na metr kwadratowy.
Pogrupować kolumnę Population w kategorie (samemu zaproponować i wyjaśnić podział).
Policzyć średnie zatowarowanie salonu w 30-dniowych oknach. (średnia z EOP dla 30 dni w każdym salonie).
Zastosować OneHotEncoding dla typu lokalizacji.
Zastosować PCA dla zmiennej z punktu pierwszego, EOP, Population tworząc dwie nowe zmienne:
sprawdzić jak dużo wariancji wyjaśnia każda z nich
zwizualizować je w zależności od Class_1
*Zaproponować własne transformacje (nie trzeba pisać kodu, wystarczy sama propozycja).
Do każdej transformacji napisz wnioski (czy nowopowstała zmienna jest użyteczna) w Markdown.