Analiza regresji¶
Wstęp¶
Algorytmy regresyjne należą do grupy uczenia nadzorowanego (Supervised Learning), inaczej mówiąc, są to algorytmy mające określoną zmienną celu (target) oraz zdefiniowane zmienne wejściowe. W odróżnieniu od klasyfikacji, w regresji zmienna celu jest liczbą rzeczywistą. Analiza regresji jest jedną z metod analizy statystycznej pozwalających opisać zależność między zmienną objaśnianą \(y \in \mathbb{R}\) (zmienna celu, zmienna zależna) oraz zmienną, bądź kilkoma, zmiennymi objaśniającymi (niezależnymi) \(x \in \mathbb{R}^d\).
Załóżmy, że chcemy wystawić na sprzedaż dom, ale nie znamy jego wartości. Powinniśmy zatem przyjrzeć się innym domom w okolicy, sprzedanym w niedalekiej przeszłości i na podstawie cen sprzedaży oraz innych czynników, takich jak ilość sypialni czy powierzchnia użytkowa, określić wartość domu, który chcemy sprzedać.
W badanym przypadku, zmienną zależną będzie cena domu, natomiast zmiennymi niezależnymi będą ilość sypialni, ilość łazienek, powierzchnia w m2, rok budowy itd. Znajdując zależność między tymi zmiennymi, będziemy w stanie określić jakie czynniki mają faktyczny wpływ na wartość domu oraz który czynnik jest najbardziej istotny, a także przewidzieć cenę za jaką sprzedamy nasz dom.
Modele regresyjne¶
Zostanie przedstawionych 6 następujących algorytmów regresyjnych:
Linear Regression
Ridge Regression
Lasso Regression
Polynomial Regression
Decision Tree
Random Forest
Skrótowo zostaną także przedstawione XGBoost, LightGBM oraz Sieci Neuronowe.
Linear Regression¶
Załóżmy, że mamy wektor \(X^T = (1, x_1, x_2,\dots, x_p)\) i chcemy przewidzieć wartość zmiennej \(y\). Model regresji liniowej przedstawia się następująco:
gdzie \(\beta_j\) nazywane są współczynnikami, a \(\epsilon_j\) jest składnikiem losowym.
Model regresji liniowej zakłada, że warunkowa wartość oczekiwana \(E(Y|X)\) jest funkcją liniową.
Najpopularniejszą metodą estymacji liniowej zależności jest metoda najmniejszych kwadratów, która wyznacza współczynniki \(\beta\) funkcji
tak, aby zminimalizować błąd kwadratowy
$$RSS(\beta) = \sum_{i=1}^N \bigg(y_i - \sum_{j=0}^p x_{ij} \beta_j\bigg)^2 = \big(X \beta - y\big)^T \big(X \beta - y\big).$$
Matematycznie problem ten można opisać wzorem:
Po zróżniczkowaniu i po przekształceniach otrzymujemy wzór na współczynniki \(\hat{\beta}\):
Poniższa ramka danych zawiera informację o cenie sprzedaży domów oraz ich powierzchni.
# Załadowanie bibliotek
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Ridge, Lasso
from sklearn.model_selection import train_test_split
import sklearn.metrics as metrics
from sklearn.preprocessing import PolynomialFeatures
from sklearn.tree import DecisionTreeRegressor, plot_tree, export_text
from sklearn.ensemble import RandomForestRegressor
# Parametry do wizualizacji
plt.rcParams["figure.figsize"] = (15,6)
# Stworzenie ramki danych
data = pd.DataFrame(([76, 350], [80, 370], [150, 540], [200, 600], [50, 300], [300, 800], [120, 490], [130, 500],
[250, 700], [120, 700]),
columns=['M2', 'Cena'])
# Wizualizacja danych
sns.scatterplot(x=data['M2'], y=data['Cena'], color='darkmagenta')
plt.show()

Możemy założyć, że istnieje liniowa zależność pomiędzy ceną domu, a powierzchnią w m2. Czyli, szukamy funkcji \(\hat{f}\) takiej, że:
y=data['Cena']
sns.scatterplot(x=data['M2'], y=y, color='darkmagenta')
sns.lineplot(data=data, x=data['M2'], y = 3 * data['M2'] + 250, color = 'lightseagreen', label = "B0 = 250, B1 = 3, RSS = " + str(np.sum(np.square(3 * data['M2'] + 250 - y))))
sns.lineplot(data=data, x=data['M2'], y = 5 * data['M2'] + 100, color = 'skyblue', label = "B0 = 100, B1 = 5, RSS = " + str(np.sum(np.square(5 * data['M2'] + 100 - y))))
sns.lineplot(data=data, x=data['M2'], y = 1 * data['M2'] + 500, color = 'pink', label = "B0 = 500, B1 = 1, RSS = " + str(np.sum(np.square(1 * data['M2'] + 500 - y))))
plt.legend()
plt.show()
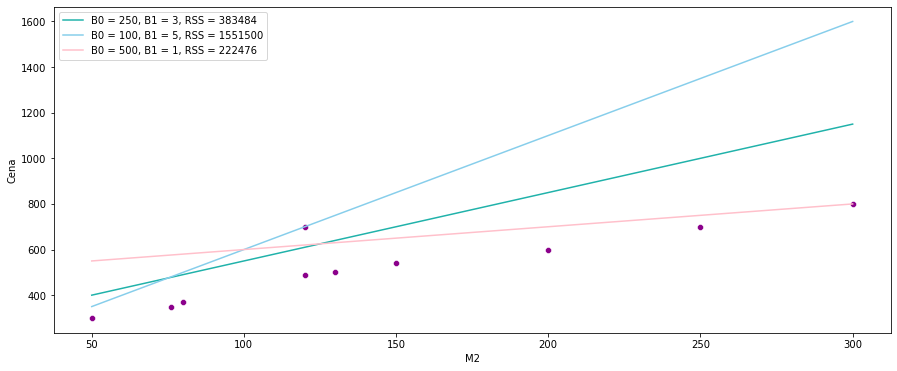
Widzimy, że najmniejszy błąd kwadratowy daje nam różowa linia. Aby znaleźć najlepsze z możliwych rozwiązań, wykorzystamy funkcję LinearRegression z biblioteki scikit-learn do znalezienia wartości współczynników \( \hat{ \beta}_0, \hat{ \beta}_1\) metodą najmniejszych kwadratów.
X = data.loc[:, 'M2']
X = X.values.reshape(-1, 1)
y = data.loc[:, 'Cena']
reg = LinearRegression(positive=False, # positive = True może mieć sens dla np. cen
fit_intercept=True) # jeśli False to brak wyrazu wolnego
reg.fit(X,y)
LinearRegression()
# Współczynnik
reg.coef_
array([1.83141395])
#Wyraz wolny
reg.intercept_
264.68330134356995
Znaleziona funkcja przedstawia się następująco:
sns.scatterplot(x=data['M2'], y=data['Cena'], color='darkmagenta')
sns.lineplot(data=data, x=data['M2'], y = reg.coef_ * data['M2'] + reg.intercept_, color = 'skyblue')
plt.show()
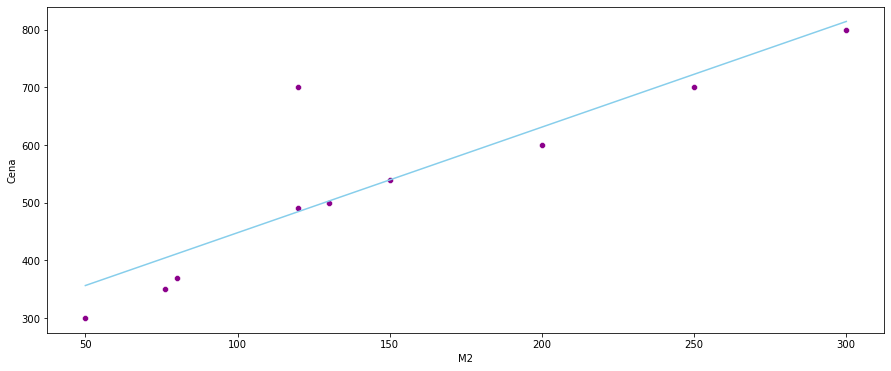
Błąd kwadratowy w tym przypadku wynosi:
y_pred = reg.predict(X)
np.sum(np.square(y_pred - y))
55928.85476647472
Ridge Regression¶
Overtfitting to nadmierne dopasowanie modelu do danych, przez co na zbiorze treningowym błąd kwadratowy będzie bliski zeru, natomiast na zbiorze testowym będzie bardzo duży. W regresji liniowej zjawisko to, wystąpić może w przypadku, gdy mamy mniej obserwacji niż predyktorów.
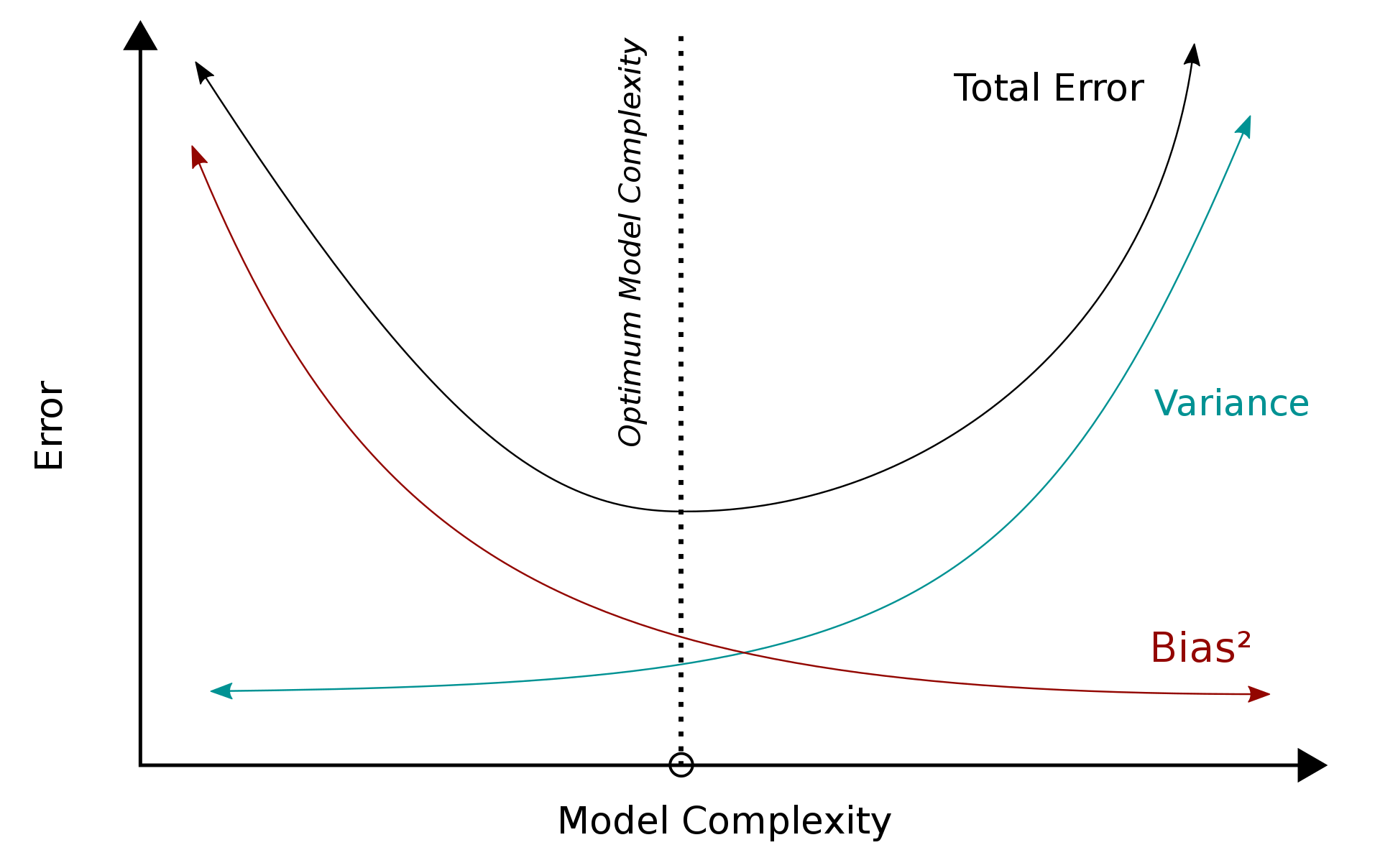 Źródło: https://en.wikipedia.org/wiki/Bias–variance_tradeoff
Źródło: https://en.wikipedia.org/wiki/Bias–variance_tradeoff
W celu rozwiązania problemu przeuczenia modelu, należy znaleźć kompromis między wariancją a przeciążeniem. Dokonać tego można dodając regularyzację do modelu.
Norma \(Lp\)
Niech \(x = (x_1, x_2, ..., x_n) \in \mathbf{X}\). Funkcje postaci
są normami dla \( 1 \leq p < \infty \). Normę \(||x||_2 \) nazywa się normą euklidesową.
Ridge Regression wykorzystuje normę euklidesową \(L2\), aby “ukarać” model za wielkość współczynników. Wtedy zamiast minimalizacji błędu resztowych sum kwadratów, minimalizowana jest funkcja:
gdzie \(\alpha\) jest hiperparametrem, nazywanym współczynnikiem kary. Przyjmuje wartości \(\alpha \geq 0\). Im wyższa jego wartość, tym model jest bardziej “karany”.
Dla celów edukacyjnych podzielimy zbiór tak, aby w zbiorze treningowym były tylko 2 obserwacje. Jest to zabieg celowy, gdyż chcemy pokazać przykład overtfittingu.
data_train, data_test = train_test_split(data, test_size = 0.8, random_state = 10)
X_train = data_train.loc[:, 'M2']
y_train = data_train.loc[:, 'Cena']
X_test = data_test.loc[:, 'M2']
y_test = data_test.loc[:, 'Cena']
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1, 1)
X = data.loc[:, 'M2']
y = data.loc[:, 'Cena']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.8, random_state = 10)
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1, 1)
Często \(\alpha\) wybiera się z przedziału \([0,1]\). W naszym przypadku wartości te są zbyt małe, więc musieliśmy ją znacznie zwiększyć. Ponieważ \(\alpha\) jest hiperparametrem, w celu znalezienia najlepszej wartości można wykorzystać walidację krzyżową.
ridge1 = Ridge(alpha = 0) #warto zwrócić uwagę, że alpha = 0 daje nam zwykłą regresję liniową
ridge1.fit(X_train, y_train)
Ridge(alpha=0)
ridge2 = Ridge(alpha = 200)
ridge2.fit(X_train, y_train)
Ridge(alpha=200)
ridge3 = Ridge(alpha = 1000)
ridge3.fit(X_train, y_train)
Ridge(alpha=1000)
ridge4 = Ridge(alpha = 5000)
ridge4.fit(X_train, y_train)
Ridge(alpha=5000)
sns.scatterplot(x=data_train['M2'], y=data_train['Cena'], color='black', marker = 's')
sns.lineplot(data=data, x=data_train['M2'], y = ridge1.coef_ * data_train['M2'] + ridge1.intercept_, color = 'gray', label = 'alpha = 0')
sns.lineplot(data=data, x=data_train['M2'], y = ridge2.coef_ * data_train['M2'] + ridge2.intercept_, color = 'lightseagreen', label = 'alpha = 200')
sns.lineplot(data=data, x=data_train['M2'], y = ridge3.coef_ * data_train['M2'] + ridge3.intercept_, color = 'plum', label = 'alpha = 1000')
sns.lineplot(data=data, x=data_train['M2'], y = ridge4.coef_ * data_train['M2'] + ridge4.intercept_, color = 'mediumvioletred', label = 'alpha = 5000')
plt.title("Zbiór treningowy")
plt.show()
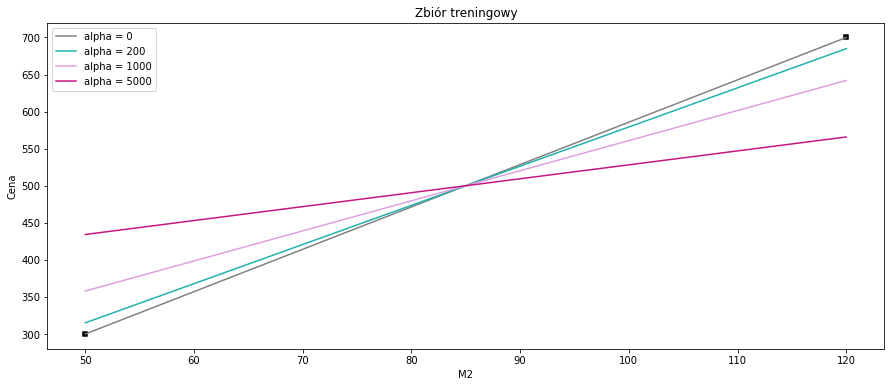
Możemy zauważyć, że na zbiorze treningowym regresja liniowa dopasowuje się idealnie do obserwacji, gdzie regresja grzbietowa wraz ze wzrostem parametru \(\alpha\) wydaje się mieć coraz gorsze dopasowanie. Zobaczmy jak to wygląda na zbiorze testowym.
sns.scatterplot(x=data_test['M2'], y=data_test['Cena'], color='darkmagenta')
sns.scatterplot(x=data_train['M2'], y=data_train['Cena'], color='black', marker = 's')
sns.lineplot(data=data, x=data['M2'], y = ridge1.coef_ * data['M2'] + ridge1.intercept_, color = 'gray', label = 'alpha = 0')
sns.lineplot(data=data, x=data['M2'], y = ridge2.coef_ * data['M2'] + ridge2.intercept_, color = 'lightseagreen', label = 'alpha = 200')
sns.lineplot(data=data, x=data['M2'], y = ridge3.coef_ * data['M2'] + ridge3.intercept_, color = 'plum', label = 'alpha = 1000')
sns.lineplot(data=data, x=data['M2'], y = ridge4.coef_ * data['M2'] + ridge4.intercept_, color = 'mediumvioletred', label = 'alpha = 5000')
plt.title("Zbiór testowy")
plt.show()
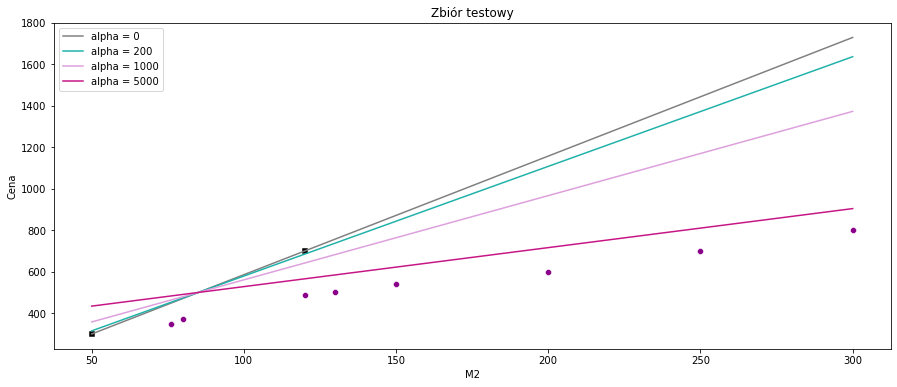
W przypadku regresji liniowej widoczny jest overfittting. Linia przechodzi dokładnie przez dwie obserwacje ze zbioru treningowego, zatem błąd kwadratowy będzie równy zero, natomiast na zbiorze testowym błąd ten będzie bardzo duży. Aby zapobiec takiej sytuacji, została wykorzystana Ridge Regression.
wyniki = pd.DataFrame(data = {'RSS':[round(np.sum(np.square(ridge1.predict(X_test) - y_test)),0),
round(np.sum(np.square(ridge2.predict(X_test) - y_test)),0),
round(np.sum(np.square(ridge3.predict(X_test) - y_test)),0),
round(np.sum(np.square(ridge4.predict(X_test) - y_test)),0)
],
'R2': [metrics.r2_score(y_test, ridge1.predict(X_test)),
metrics.r2_score(y_test, ridge2.predict(X_test)),
metrics.r2_score(y_test, ridge3.predict(X_test)),
metrics.r2_score(y_test, ridge4.predict(X_test))],
'MAE': [metrics.mean_absolute_error(y_test, ridge1.predict(X_test)),
metrics.mean_absolute_error(y_test, ridge2.predict(X_test)),
metrics.mean_absolute_error(y_test, ridge3.predict(X_test)),
metrics.mean_absolute_error(y_test, ridge4.predict(X_test))]},
index=['alpha = 0', 'alpha = 200', 'alpha = 1000', 'alpha = 5000']).style.background_gradient(cmap='Blues')
wyniki
| RSS | R2 | MAE | |
|---|---|---|---|
| alpha = 0 | 1964561.000000 | -10.849875 | 403.392857 |
| alpha = 200 | 1615208.000000 | -8.742643 | 369.646226 |
| alpha = 1000 | 814095.000000 | -3.910474 | 273.786232 |
| alpha = 5000 | 88315.000000 | 0.467297 | 103.296980 |
Widzimy, że im większy współczynnik kary, tym model jest bardziej dopasowany do pozostałych obserwacji.
Lasso Regression¶
Lasso Regression jest kolejną metodą służącą do redukcji overfittingu, ale tym razem wykorzystującą do regularyzacji normę \(L1\).
Funkcja celu modelu Lasso Regression wygląda następująco:
lasso1 = Lasso(alpha = 0.001)
lasso1.fit(X_train, y_train)
Lasso(alpha=0.001)
lasso2 = Lasso(alpha = 200)
lasso2.fit(X_train, y_train)
Lasso(alpha=200)
lasso3 = Lasso(alpha = 1000)
lasso3.fit(X_train, y_train)
Lasso(alpha=1000)
lasso4 = Lasso(alpha = 5000)
lasso4.fit(X_train, y_train)
Lasso(alpha=5000)
sns.scatterplot(x=data_test['M2'], y=data_test['Cena'], color='darkmagenta')
sns.scatterplot(x=data_train['M2'], y=data_train['Cena'], color='skyblue')
sns.lineplot(data=data, x=data['M2'], y = lasso1.coef_ * data['M2'] + lasso1.intercept_, color = 'gray', label = 'alpha = 0')
sns.lineplot(data=data, x=data['M2'], y = lasso2.coef_ * data['M2'] + lasso2.intercept_, color = 'lightseagreen', label = 'alpha = 200')
sns.lineplot(data=data, x=data['M2'], y = lasso3.coef_ * data['M2'] + lasso3.intercept_, color = 'plum', label = 'alpha = 1000')
sns.lineplot(data=data, x=data['M2'], y = lasso4.coef_ * data['M2'] + lasso4.intercept_, color = 'mediumvioletred', label = 'alpha = 5000')
plt.title("Zbiór testowy")
plt.show()
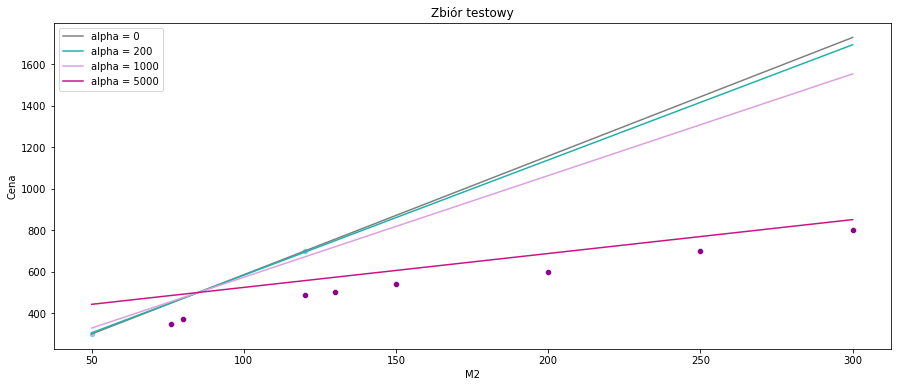
Tutaj również możemy wyciągnąć wniosek, że im większy współczynnik kary, tym dopasowanie modelu jest lepsze.
wyniki2 = pd.DataFrame(data = {'RSS':[round(np.sum(np.square(lasso1.predict(X_test) - y_test)),0),
round(np.sum(np.square(lasso2.predict(X_test) - y_test)),0),
round(np.sum(np.square(lasso3.predict(X_test) - y_test)),0),
round(np.sum(np.square(lasso4.predict(X_test) - y_test)),0)
],
'R2': [metrics.r2_score(y_test, lasso1.predict(X_test)),
metrics.r2_score(y_test, lasso2.predict(X_test)),
metrics.r2_score(y_test, lasso3.predict(X_test)),
metrics.r2_score(y_test, lasso4.predict(X_test))],
'MAE': [metrics.mean_absolute_error(y_test, lasso1.predict(X_test)),
metrics.mean_absolute_error(y_test, lasso2.predict(X_test)),
metrics.mean_absolute_error(y_test, lasso3.predict(X_test)),
metrics.mean_absolute_error(y_test, lasso4.predict(X_test))]},
index=['alpha = 0', 'alpha = 200', 'alpha = 1000', 'alpha = 5000']).style.background_gradient(cmap='Blues')
wyniki2
| RSS | R2 | MAE | |
|---|---|---|---|
| alpha = 0 | 1964561.000000 | -10.849871 | 403.392793 |
| alpha = 200 | 1828182.000000 | -10.027261 | 390.617347 |
| alpha = 1000 | 1332914.000000 | -7.039895 | 339.515306 |
| alpha = 5000 | 62549.000000 | 0.622717 | 84.005102 |
Używanie normy \(L1\) może także spowodować, że w przypadku modelu o kilku zmiennych objaśniających, współczynniki dla niektórych z nich zostaną wyzerowane.
Interpretacja geometryczna
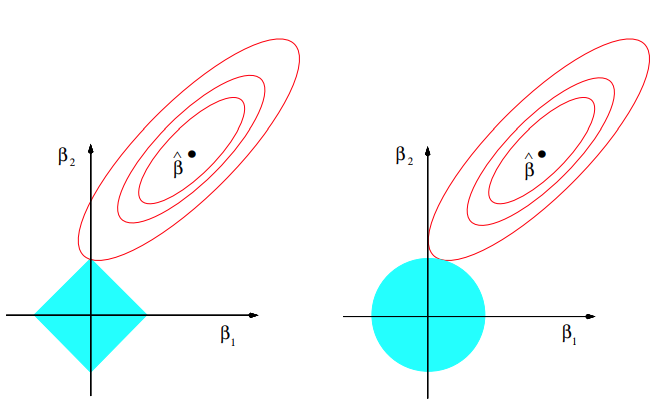
Źródło: The Elements of Statistical Learning Trevor Hastie, Robert Tibshirani, Jerome Friedman, Second Edition.
Czerwone elipsy odpowiadają za błąd kwadratowy, natomiast niebieskie kolory przedstawiają kulę w metrykach \(L1\) i \(L2\) odpowiednio. W związku z tym, że kula w metryce \(L1\) ma kwadratowy kształt, to kiedy suma resztowa kwadratów znajdzie się w jednym z rogów, współczynnik jest zerowany. W Ridge Regression współczynniki te zbliżają się do zera, ale nigdy nie osiągają wartości równej 0.
Z tego też względu Lasso Regression jest często wykorzystywane również do wyboru zmiennych modelu.
Polynomial Regression¶
Weźmy teraz nowy, nieco bardziej abstrakcyjny zbiór danych, zdefiniowany jako argumenty i wartości pewnej funkcji, przy czym do wartości dodajmy nieco szumu losowego.
N = 125
np.random.seed(23)
x = np.random.rand(N,1) * 2 - 1
noise = np.random.normal(0,0.2,size=(N,1))
y = x ** 2 + 0.5 * np.sin(x) + noise
x_train, x_valid, y_train, y_valid = train_test_split(x, y, random_state = 11, test_size = 0.2)
plt.scatter(x_train, y_train, c='b', marker='o')
plt.title('Zbior treningowy')
plt.show()
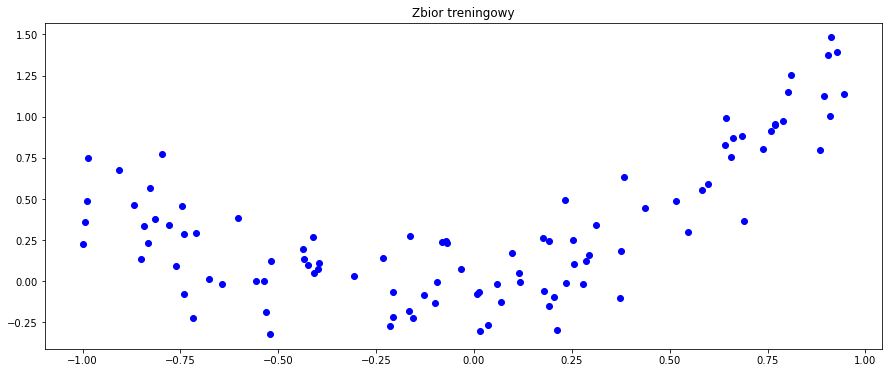
Spróbujmy dopasować do tych danych model regresji liniowej.
reg2 = LinearRegression(positive=False,
fit_intercept=True)
reg2.fit(x_train,y_train)
LinearRegression()
print("Coefficient: ", reg2.coef_)
print("Intercept: ", reg2.intercept_)
Coefficient: [[0.38355249]]
Intercept: [0.32220545]
Sprawdźmy dopasowanie modelu do danych treningowych.
plt.scatter(x_train, y_train, c='b', marker='o')
plt.plot(x_train, x_train * reg2.coef_ + reg2.intercept_, c='r')
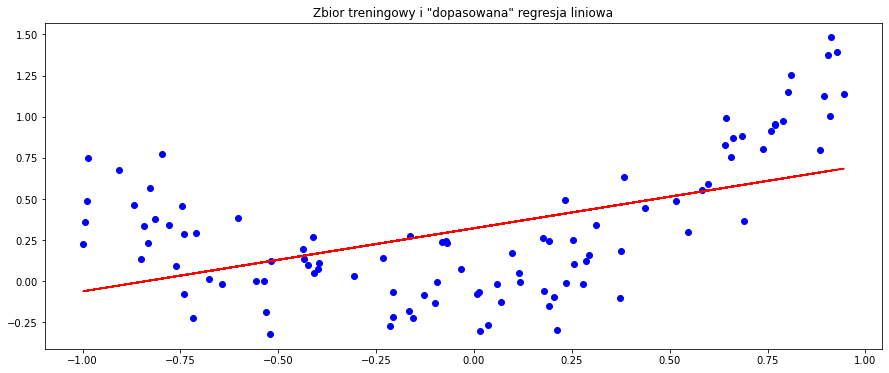
plt.title('Zbior treningowy i "dopasowana" regresja liniowa')
plt.show()
preds3 = reg2.predict(x_valid)
wyniki3 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds3 - y_valid))
],
'R2': [metrics.r2_score(y_valid, preds3)
],
'MAE': [metrics.mean_absolute_error(y_valid, preds3)]},
index=['lin_reg']).style.background_gradient(cmap='Blues')
wyniki3
| RSS | R2 | MAE | |
|---|---|---|---|
| lin_reg | 2.193040 | 0.441041 | 0.246324 |
Jak widzimy, model regresji liniowej nie dał dobrego dopasowania do nowego zbioru danych. Stało się tak dlatego, że relacja pomiędzy zmienną objaśniającą a zmienną objaśnianą po prostu nie jest liniowa, a co za tym idzie, modele liniowe nie będą dawać nam zadowalającej skuteczności. W takim wypadku, siłą rzeczy, powinniśmy posłużyć się modelami nieliniowymi. Pierwszym z nich jest regresja wielomianowa.
Najprostszą formą regresji wielomianowej jest regresja kwadratowa, której równanie jest dane jako
gdzie oczywiście zakładamy, że mamy jedną zmienną objaśniającą i jedną zmienną objaśnianą. W ogólności, możemy modelować oczekiwaną wartość \(y\) wielomianem n-tego stopnia, uzyskując równanie ogólne postaci
Można zauważyć, że z punktu widzenia estymacji ten model jest liniowy, gdyż funkcja regresji jest liniowa względem nieznanych parametrów \(\beta_0,\beta_1,...,\beta_n\). Zatem, stosując metodę najmniejszych kwadratów, taki model może być traktowany jak model regresji liniowej wielu zmiennych, przy założeniu, że \(x,x^2,...x^n\) są różnymi, niezależnymi zmiennymi w takim modelu.
Podobnie jak wcześniej, współczynniki \(\beta\) są dane wzorem
Na początek zamodelujemy dane regresją kwadratową.
poly = PolynomialFeatures(degree = 2)
x_train_poly = poly.fit_transform(x_train)
x_valid_poly = poly.transform(x_valid)
Funkcja PolynomialFeatures wyznacza wielomiany złożone z cech numerycznych zadanej ramki danych. W naszym wypadku, jeśli mamy do dyspozycji jedną cechę \(x\) oraz wyznaczamy cechy wielomianowe drugiego stopnia, powstanie nam nowa cecha \(x^2\) oraz dodatkowa cecha, która dla każdego rekordu przyjmuje wartość \(1\). Natomiast, jeśli mielibyśmy dwie cechy \([x_1,x_2]\), to lista nowych cech wyglądałaby następująco: \([1,x_1,x_2,x_1^2,x_1 x_2,x_2^2]\), gdzie wszystkie cechy trafiłyby do modelu.
reg3 = LinearRegression(positive=False,
fit_intercept=True)
reg3.fit(x_train_poly,y_train)
LinearRegression()
print("Coefficient: ", reg3.coef_)
print("Intercept: ", reg3.intercept_)
Coefficient: [[0. 0.42997276 1.02119995]]
Intercept: [-0.01564705]
y_pred_reg3 = reg3.predict(x_valid_poly)
df_plot_squarereg = pd.DataFrame(
{'x': np.reshape(x_train, (100,)),
'prediction': x_train_poly[:,1] * reg3.coef_[:,1] + x_train_poly[:,2] * reg3.coef_[:,2] + reg3.intercept_
}).sort_values(by = 'x')
plt.scatter(x_train, y_train, c='b', marker='o')
plt.plot(df_plot_squarereg['x'], df_plot_squarereg['prediction'], c='r')
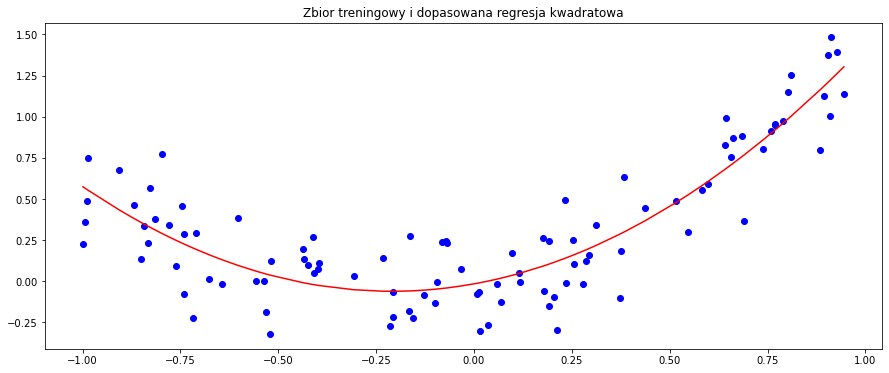
plt.title('Zbior treningowy i dopasowana regresja kwadratowa')
plt.show()
preds4 = reg3.predict(x_valid_poly)
wyniki4 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds3 - y_valid)),
np.sum(np.square(preds4 - y_valid))
],
'R2': [metrics.r2_score(y_valid, preds3),
metrics.r2_score(y_valid, preds4)
],
'MAE': [metrics.mean_absolute_error(y_valid, preds3),
metrics.mean_absolute_error(y_valid, preds4)]},
index=['lin_reg', 'square_reg']).style.background_gradient(cmap='Blues')
wyniki4
| RSS | R2 | MAE | |
|---|---|---|---|
| lin_reg | 2.193040 | 0.441041 | 0.246324 |
| square_reg | 0.710297 | 0.818960 | 0.131138 |
Zgodnie z oczekiwaniami, model regresji kwadratowej dał o wiele lepsze dopasowanie. Teraz sprawdźmy jeszcze co stanie się, gdy znacznie zwiększymy stopień wielomianu dla powyższych danych.
poly100 = PolynomialFeatures(degree = 100)
x_train_poly100 = poly100.fit_transform(x_train)
x_valid_poly100 = poly100.transform(x_valid)
reg4 = LinearRegression(positive=False,
fit_intercept=True)
reg4.fit(x_train_poly100,y_train)
LinearRegression()
print("Coefficient: ", reg4.coef_)
print("Intercept: ", reg4.intercept_)
Coefficient: [[-7.15562755e+10 -6.04924150e+00 5.17498454e+01 1.16497512e+03
-6.55481187e+03 -7.73416858e+04 3.54270354e+05 2.60947476e+06
-1.06153968e+07 -5.15748797e+07 1.97935959e+08 6.47113715e+08
-2.44480756e+09 -5.40682430e+09 2.07908420e+10 3.07876364e+10
-1.24506316e+11 -1.19185324e+11 5.29206690e+11 3.00218957e+11
-1.58090593e+12 -4.16243830e+11 3.19031616e+12 3.18156635e+10
-3.87420709e+12 9.08879307e+11 1.64147023e+12 -1.16637376e+12
2.06101996e+12 -2.85368060e+11 -2.08169773e+12 1.31471694e+12
-1.56817637e+12 3.06138638e+11 1.54752668e+12 -1.24159351e+12
1.86220933e+12 -8.00740459e+11 -4.44950761e+11 7.36761622e+11
-1.93288151e+12 1.29248908e+12 -9.67945021e+11 3.28618281e+11
8.83288802e+11 -9.59862560e+11 1.66832443e+12 -1.23492612e+12
8.88758912e+11 -3.79171659e+11 -6.23851346e+11 7.58837455e+11
-1.46568145e+12 1.25199247e+12 -1.13529910e+12 7.89149855e+11
-5.22905183e+10 -2.29502460e+11 1.02122440e+12 -1.03888611e+12
1.35360331e+12 -1.14510624e+12 8.08507137e+11 -5.58382492e+11
-1.59520359e+11 3.19019961e+11 -1.03050938e+12 1.01752328e+12
-1.24669536e+12 1.11200930e+12 -7.76974487e+11 6.03977680e+11
6.99969406e+10 -1.91461478e+11 9.15181861e+11 -8.83511308e+11
1.23831169e+12 -1.09517370e+12 9.00218897e+11 -7.09562547e+11
4.87764642e+10 1.30121527e+10 -7.88456681e+11 7.11113943e+11
-1.25970424e+12 1.04578877e+12 -1.02028821e+12 7.14134016e+11
-1.08818085e+11 -5.67014732e+10 9.59222688e+11 -8.01201614e+11
1.47676285e+12 -8.87548710e+11 8.34557044e+11 -9.10072833e+10
-9.03694115e+11 9.75314675e+11 -2.09595731e+12 -2.65695997e+11
1.32627740e+12]]
Intercept: [7.15562755e+10]
formula = 0
for i in range(1,101):
formula = formula + x_train_poly100[:,i] * reg4.coef_[:,i]
df_plot_squarereg2 = pd.DataFrame(
{'x': np.reshape(x_train, (100,)),
'prediction': formula + reg3.intercept_
}).sort_values(by = 'x')
plt.scatter(x_train, y_train, c='b', marker='o')
plt.plot(df_plot_squarereg2['x'], df_plot_squarereg2['prediction'], c='r')
plt.title('Zbior treningowy i dopasowana (?) regresja wielomianowa')
plt.show()

Sprawdźmy wartości metryk na zbiorze walidacyjnym.
preds5 = reg4.predict(x_valid_poly100)
wyniki5 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds4 - y_valid)),
np.sum(np.square(preds5 - y_valid))
],
'R2': [metrics.r2_score(y_valid, preds4),
metrics.r2_score(y_valid, preds5)
],
'MAE': [metrics.mean_absolute_error(y_valid, preds4),
metrics.mean_absolute_error(y_valid, preds5)]},
index=['square_reg', 'poly_reg']).style.background_gradient(cmap='Blues')
wyniki5
| RSS | R2 | MAE | |
|---|---|---|---|
| square_reg | 0.710297 | 0.818960 | 0.131138 |
| poly_reg | 7767154286.393160 | -1979682693.614666 | 3525.458606 |
Jak można było się spodziewać, model jest teraz mocno przeuczony. Stosując model regresji wielomianowej należy pamiętać o ryzyku przeuczenia modelu, które wzrasta wraz ze wzrostem stopnia wielomianu. Oczywiście, zapobiec temu problemowi może regularyzacja, którą można stosować analogicznie jak w regresji liniowej.
Decision Trees¶
Drzewa decyzyjne to algorytm modelujący dane nieliniowo, nadający się zarówno do klasyfikacji, jak i regresji. Przyjmują one dowolne typy danych, numeryczne i kategoryczne, bez założeń dotyczących rozkładu i bez potrzeby ich wstępnego przetwarzania. Algorytm ten jest względnie łatwy w użyciu, a jego wyniki są w miarę proste w interpretacji. Po dopasowaniu modelu, przewidywanie wyników jest szybkim procesem. Jednak drzewa decyzyjne mają też swoje wady, mają one tendencję do przeuczania (zwłaszcza, gdy nie są przycinane).
Konstrukcja
Drzewa decyzyjnie można podsumować jako serię pytań/warunków dla ustalonego rekordu w danych treningowych, które kończą się zwróceniem przez drzewo informacji o oczekiwanej wartości (klasie) zmiennej objaśnianej dla owego rekordu. Składają się one z węzłów, gałęzi i liści. Konstrukcję zaczyna się od korzenia, czyli pierwszego węzła. Następnie tworzymy gałęzie odpowiadające różnym odpowiedziom na to pytanie, i powtarzamy te czynności do momentu, gdy drzewo zwraca nam oczekiwaną wartość zmiennej objaśnianej. Jeśli w liściu znalazła się więcej niż jedna wartość, wyznaczamy średnią z owych wartości jako wskazaną przez drzewo. Drzewa stosowane w regresji nazywa się czasem drzewami regresyjnymi.
Przycinanie liści
Żeby zapobiec zbyt dużemu rozrostowi drzewa decyzyjnego, który może doprowadzić do małego poziomu generalizacji oraz spowolnienia działania algorytmu, stosuje się tak zwane przycianie drzewa (ang pruning). Polega ono na usuwaniu zbędnych elementów z drzewa po jego utworzeniu. Wyróżnia się dwa podstawowe rodzaje przycinania:
przycinanie wsteczne, polegające na wygenerowaniu drzewa, które jest bardzo dobrze dopasowane do zbioru treningowego, a następnie usuwanie od dołu najmniej efektywnych węzłów,
przycinanie w przód, polegające na wstrzymaniu dalszej rozbudowy danej gałęzi jeśli na węźle znajduje się ilość próbek zaklasyfikowanych do danej klasy, przekracza wyznaczony próg.
Miary wyboru podziału drzewa regresyjnego
W drzewach decyzyjnych dla klasyfikacji, drzewo musi zadawać właściwe pytania we właściwym momencie, aby dokładnie klasyfikować dane. W tym celu korzysta się z miar entropii, przyrostu informacji lub indeksu Giniego. Jednak ponieważ teraz przewidujemy wartości ciągłych zmiennych, potrzebujemy innej miary. Takiej, która określa odchylenie predykcji od rzeczywistej wartości. Naturalnym wyborem zdaje się być błąd średniokwadratowy, dany dla przypomnienia wzorem
gdzie \(Y\) to wartości znajdujące się w węźle drzewa, który chcemy dzielić, zaś \(\hat{Y}\) jest ich średnią. Wybierając podział należy ten błąd zminimalizować. Alternatywnie korzysta się z następujących kryteriów: MSE Friedmana, MAE oraz Poisson deviance.
Przejdźmy przez przykładowy, ręczny wybór podziału.
df_example = pd.DataFrame({'X': list(range(1,15)), 'Y': [1,1.2,1.4,1.1,1,5.5,6.1,6.7,6.4,6,6,3,3.2,3.1]})
df_example
| X | Y | |
|---|---|---|
| 0 | 1 | 1.0 |
| 1 | 2 | 1.2 |
| 2 | 3 | 1.4 |
| 3 | 4 | 1.1 |
| 4 | 5 | 1.0 |
| 5 | 6 | 5.5 |
| 6 | 7 | 6.1 |
| 7 | 8 | 6.7 |
| 8 | 9 | 6.4 |
| 9 | 10 | 6.0 |
| 10 | 11 | 6.0 |
| 11 | 12 | 3.0 |
| 12 | 13 | 3.2 |
| 13 | 14 | 3.1 |
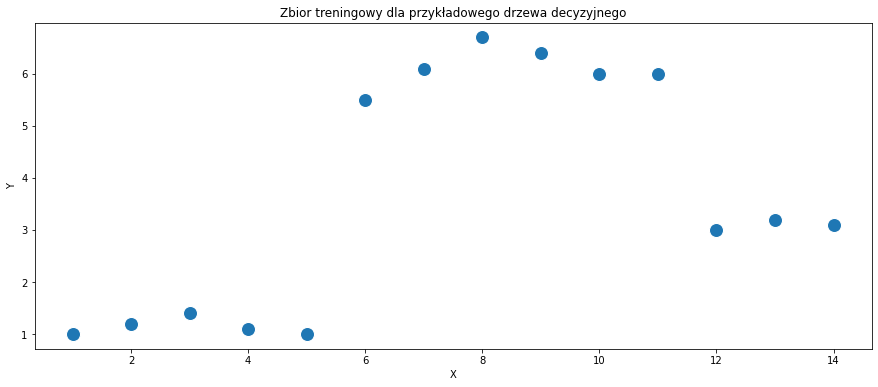
sns.scatterplot(x = df_example['X'], y = df_example['Y'], s = 200)
plt.title('Zbior treningowy dla przykładowego drzewa decyzyjnego')
plt.show()
Początkowa wartość \(MSE\) wynosi
print('MSE =', (np.sum((df_example['Y'] - np.mean(df_example['Y'])) ** 2))/ df_example.shape[0])
MSE = 4.989234693877552
Dopiero zaczynamy budować drzewo, zatem w aktualnym węźle znajdują się wszystkie wartości \(X\). Dla takiego zbioru danych, wszystkie możliwe warunki mają postać “Czy \(X\) jest większe/mniejsze niż \(a\)?”, gdzie \(a\) to może być dowolna liczba z przedziału \((0,14)\). Dla uproszczenia będziemy rozpatrywać liczby \(1.5,2.5,...,13.5\). Należy podzielić zbiór na każdy z 13 możliwych sposobów, wyznaczyć średnie wartości w węzłach jako aktualne wartości predykcji dla danego \(X\), wyznaczyć wszystkie wartości \(MSE\) oraz wybrać podział, dla którego ten błąd jest najmniejszy.
cut_list = []
mse_list = []
for i in range(1,14):
cut = i + 0.5
cut_list.append(cut)
values_below = df_example[df_example['X'] < cut]
values_above = df_example[df_example['X'] > cut]
pred_below = np.mean(values_below['Y'])
pred_above = np.mean(values_above['Y'])
sse = sum((values_below['Y'] - pred_below) ** 2) + sum((values_above['Y'] - pred_above) ** 2)
mse = sse / len(df_example)
mse_list.append(mse)
df_tree_cut = pd.DataFrame({'cut': cut_list, 'mse': mse_list})
df_tree_cut
| cut | mse | |
|---|---|---|
| 0 | 1.5 | 4.431429 |
| 1 | 2.5 | 3.868750 |
| 2 | 3.5 | 3.294416 |
| 3 | 4.5 | 2.453393 |
| 4 | 5.5 | 1.368635 |
| 5 | 6.5 | 2.488006 |
| 6 | 7.5 | 3.497347 |
| 7 | 8.5 | 4.349167 |
| 8 | 9.5 | 4.810540 |
| 9 | 10.5 | 4.982250 |
| 10 | 11.5 | 4.893377 |
| 11 | 12.5 | 4.940119 |
| 12 | 13.5 | 4.962198 |
sns.scatterplot(x = df_tree_cut['cut'], y = df_tree_cut['mse'], s = 200, hue = df_tree_cut['mse'], palette = 'crest')
plt.title('Możliwe podziały dla pierwszego węzła drzewa decyzyjnego')
plt.show()
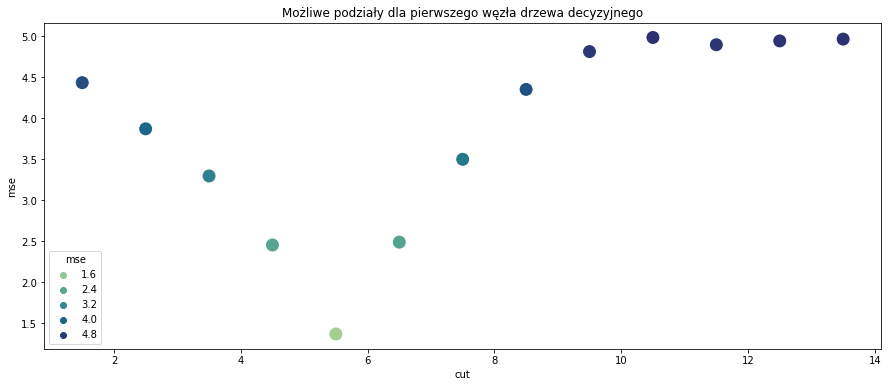
Stąd otrzymujemy, że pierwszy węzeł drzewa powinien zawierać warunek
“Czy \(X\) jest większe/mniejsze niż \(5.5\)?”
Stwórzmy teraz całe drzewo regresyjne na zbiorze danych, z którego korzystaliśmy przy okazji regresji wielomianowej. Tym razem już automatycznie.
dt_reg = DecisionTreeRegressor()
dt_reg.fit(x_train, y_train)
preds_dt = dt_reg.predict(x_valid)
wyniki6 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds4 - y_valid)),
np.sum(np.square(np.reshape(preds_dt, (25,1)) - y_valid))
],
'R2': [metrics.r2_score(y_valid, preds4),
metrics.r2_score(y_valid, preds_dt)
],
'MAE': [metrics.mean_absolute_error(y_valid, preds4),
metrics.mean_absolute_error(y_valid, preds_dt)]},
index=['square_reg', 'dt_reg']).style.background_gradient(cmap='Blues')
wyniki6
| RSS | R2 | MAE | |
|---|---|---|---|
| square_reg | 0.710297 | 0.818960 | 0.131138 |
| dt_reg | 1.442085 | 0.632443 | 0.197432 |
Wyniki modelu na zbiorze walidacyjnym nie są dobre. Zwizualizujmy stworzone drzewo żeby sprawdzić, co mogło pójść nie tak.
print(export_text(dt_reg))
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_reg, filled=True)
|--- feature_0 <= 0.56
| |--- feature_0 <= -0.74
| | |--- feature_0 <= -0.79
| | | |--- feature_0 <= -0.81
| | | | |--- feature_0 <= -0.86
| | | | | |--- feature_0 <= -0.99
| | | | | | |--- feature_0 <= -1.00
| | | | | | | |--- value: [0.22]
| | | | | | |--- feature_0 > -1.00
| | | | | | | |--- value: [0.36]
| | | | | |--- feature_0 > -0.99
| | | | | | |--- feature_0 <= -0.89
| | | | | | | |--- feature_0 <= -0.99
| | | | | | | | |--- value: [0.49]
| | | | | | | |--- feature_0 > -0.99
| | | | | | | | |--- feature_0 <= -0.95
| | | | | | | | | |--- value: [0.75]
| | | | | | | | |--- feature_0 > -0.95
| | | | | | | | | |--- value: [0.67]
| | | | | | |--- feature_0 > -0.89
| | | | | | | |--- value: [0.46]
| | | | |--- feature_0 > -0.86
| | | | | |--- feature_0 <= -0.83
| | | | | | |--- feature_0 <= -0.85
| | | | | | | |--- value: [0.14]
| | | | | | |--- feature_0 > -0.85
| | | | | | | |--- feature_0 <= -0.84
| | | | | | | | |--- value: [0.33]
| | | | | | | |--- feature_0 > -0.84
| | | | | | | | |--- value: [0.23]
| | | | | |--- feature_0 > -0.83
| | | | | | |--- feature_0 <= -0.82
| | | | | | | |--- value: [0.56]
| | | | | | |--- feature_0 > -0.82
| | | | | | | |--- value: [0.38]
| | | |--- feature_0 > -0.81
| | | | |--- value: [0.77]
| | |--- feature_0 > -0.79
| | | |--- feature_0 <= -0.75
| | | | |--- feature_0 <= -0.77
| | | | | |--- value: [0.34]
| | | | |--- feature_0 > -0.77
| | | | | |--- value: [0.09]
| | | |--- feature_0 > -0.75
| | | | |--- feature_0 <= -0.74
| | | | | |--- value: [0.46]
| | | | |--- feature_0 > -0.74
| | | | | |--- value: [0.29]
| |--- feature_0 > -0.74
| | |--- feature_0 <= 0.38
| | | |--- feature_0 <= 0.22
| | | | |--- feature_0 <= 0.19
| | | | | |--- feature_0 <= 0.08
| | | | | | |--- feature_0 <= -0.01
| | | | | | | |--- feature_0 <= -0.09
| | | | | | | | |--- feature_0 <= -0.22
| | | | | | | | | |--- feature_0 <= -0.71
| | | | | | | | | | |--- feature_0 <= -0.73
| | | | | | | | | | | |--- value: [-0.08]
| | | | | | | | | | |--- feature_0 > -0.73
| | | | | | | | | | | |--- value: [-0.22]
| | | | | | | | | |--- feature_0 > -0.71
| | | | | | | | | | |--- feature_0 <= -0.69
| | | | | | | | | | | |--- value: [0.29]
| | | | | | | | | | |--- feature_0 > -0.69
| | | | | | | | | | | |--- truncated branch of depth 7
| | | | | | | | |--- feature_0 > -0.22
| | | | | | | | | |--- feature_0 <= -0.16
| | | | | | | | | | |--- feature_0 <= -0.21
| | | | | | | | | | | |--- value: [-0.27]
| | | | | | | | | | |--- feature_0 > -0.21
| | | | | | | | | | | |--- truncated branch of depth 3
| | | | | | | | | |--- feature_0 > -0.16
| | | | | | | | | | |--- feature_0 <= -0.16
| | | | | | | | | | | |--- value: [0.28]
| | | | | | | | | | |--- feature_0 > -0.16
| | | | | | | | | | | |--- truncated branch of depth 4
| | | | | | | |--- feature_0 > -0.09
| | | | | | | | |--- feature_0 <= -0.05
| | | | | | | | | |--- feature_0 <= -0.07
| | | | | | | | | | |--- feature_0 <= -0.08
| | | | | | | | | | | |--- value: [0.24]
| | | | | | | | | | |--- feature_0 > -0.08
| | | | | | | | | | | |--- value: [0.24]
| | | | | | | | | |--- feature_0 > -0.07
| | | | | | | | | | |--- value: [0.23]
| | | | | | | | |--- feature_0 > -0.05
| | | | | | | | | |--- value: [0.07]
| | | | | | |--- feature_0 > -0.01
| | | | | | | |--- feature_0 <= 0.01
| | | | | | | | |--- feature_0 <= 0.01
| | | | | | | | | |--- value: [-0.08]
| | | | | | | | |--- feature_0 > 0.01
| | | | | | | | | |--- value: [-0.06]
| | | | | | | |--- feature_0 > 0.01
| | | | | | | | |--- feature_0 <= 0.05
| | | | | | | | | |--- feature_0 <= 0.03
| | | | | | | | | | |--- value: [-0.30]
| | | | | | | | | |--- feature_0 > 0.03
| | | | | | | | | | |--- value: [-0.27]
| | | | | | | | |--- feature_0 > 0.05
| | | | | | | | | |--- feature_0 <= 0.06
| | | | | | | | | | |--- value: [-0.02]
| | | | | | | | | |--- feature_0 > 0.06
| | | | | | | | | | |--- value: [-0.12]
| | | | | |--- feature_0 > 0.08
| | | | | | |--- feature_0 <= 0.19
| | | | | | | |--- feature_0 <= 0.18
| | | | | | | | |--- feature_0 <= 0.15
| | | | | | | | | |--- feature_0 <= 0.11
| | | | | | | | | | |--- value: [0.17]
| | | | | | | | | |--- feature_0 > 0.11
| | | | | | | | | | |--- feature_0 <= 0.12
| | | | | | | | | | | |--- value: [0.05]
| | | | | | | | | | |--- feature_0 > 0.12
| | | | | | | | | | | |--- value: [-0.00]
| | | | | | | | |--- feature_0 > 0.15
| | | | | | | | | |--- value: [0.26]
| | | | | | | |--- feature_0 > 0.18
| | | | | | | | |--- value: [-0.06]
| | | | | | |--- feature_0 > 0.19
| | | | | | | |--- value: [0.25]
| | | | |--- feature_0 > 0.19
| | | | | |--- feature_0 <= 0.21
| | | | | | |--- feature_0 <= 0.20
| | | | | | | |--- value: [-0.15]
| | | | | | |--- feature_0 > 0.20
| | | | | | | |--- value: [-0.09]
| | | | | |--- feature_0 > 0.21
| | | | | | |--- value: [-0.30]
| | | |--- feature_0 > 0.22
| | | | |--- feature_0 <= 0.23
| | | | | |--- value: [0.49]
| | | | |--- feature_0 > 0.23
| | | | | |--- feature_0 <= 0.24
| | | | | | |--- value: [-0.01]
| | | | | |--- feature_0 > 0.24
| | | | | | |--- feature_0 <= 0.34
| | | | | | | |--- feature_0 <= 0.30
| | | | | | | | |--- feature_0 <= 0.25
| | | | | | | | | |--- value: [0.25]
| | | | | | | | |--- feature_0 > 0.25
| | | | | | | | | |--- feature_0 <= 0.28
| | | | | | | | | | |--- feature_0 <= 0.27
| | | | | | | | | | | |--- value: [0.10]
| | | | | | | | | | |--- feature_0 > 0.27
| | | | | | | | | | | |--- value: [-0.01]
| | | | | | | | | |--- feature_0 > 0.28
| | | | | | | | | | |--- feature_0 <= 0.29
| | | | | | | | | | | |--- value: [0.13]
| | | | | | | | | | |--- feature_0 > 0.29
| | | | | | | | | | | |--- value: [0.16]
| | | | | | | |--- feature_0 > 0.30
| | | | | | | | |--- value: [0.34]
| | | | | | |--- feature_0 > 0.34
| | | | | | | |--- feature_0 <= 0.37
| | | | | | | | |--- value: [-0.10]
| | | | | | | |--- feature_0 > 0.37
| | | | | | | | |--- value: [0.18]
| | |--- feature_0 > 0.38
| | | |--- feature_0 <= 0.41
| | | | |--- value: [0.63]
| | | |--- feature_0 > 0.41
| | | | |--- feature_0 <= 0.53
| | | | | |--- feature_0 <= 0.48
| | | | | | |--- value: [0.44]
| | | | | |--- feature_0 > 0.48
| | | | | | |--- value: [0.49]
| | | | |--- feature_0 > 0.53
| | | | | |--- value: [0.30]
|--- feature_0 > 0.56
| |--- feature_0 <= 0.80
| | |--- feature_0 <= 0.62
| | | |--- feature_0 <= 0.59
| | | | |--- value: [0.56]
| | | |--- feature_0 > 0.59
| | | | |--- value: [0.59]
| | |--- feature_0 > 0.62
| | | |--- feature_0 <= 0.75
| | | | |--- feature_0 <= 0.69
| | | | | |--- feature_0 <= 0.65
| | | | | | |--- feature_0 <= 0.64
| | | | | | | |--- value: [0.82]
| | | | | | |--- feature_0 > 0.64
| | | | | | | |--- value: [0.99]
| | | | | |--- feature_0 > 0.65
| | | | | | |--- feature_0 <= 0.66
| | | | | | | |--- value: [0.75]
| | | | | | |--- feature_0 > 0.66
| | | | | | | |--- feature_0 <= 0.67
| | | | | | | | |--- value: [0.87]
| | | | | | | |--- feature_0 > 0.67
| | | | | | | | |--- value: [0.89]
| | | | |--- feature_0 > 0.69
| | | | | |--- feature_0 <= 0.71
| | | | | | |--- value: [0.36]
| | | | | |--- feature_0 > 0.71
| | | | | | |--- value: [0.81]
| | | |--- feature_0 > 0.75
| | | | |--- feature_0 <= 0.76
| | | | | |--- value: [0.91]
| | | | |--- feature_0 > 0.76
| | | | | |--- feature_0 <= 0.78
| | | | | | |--- feature_0 <= 0.77
| | | | | | | |--- value: [0.95]
| | | | | | |--- feature_0 > 0.77
| | | | | | | |--- value: [0.96]
| | | | | |--- feature_0 > 0.78
| | | | | | |--- value: [0.97]
| |--- feature_0 > 0.80
| | |--- feature_0 <= 0.91
| | | |--- feature_0 <= 0.85
| | | | |--- feature_0 <= 0.81
| | | | | |--- value: [1.15]
| | | | |--- feature_0 > 0.81
| | | | | |--- value: [1.26]
| | | |--- feature_0 > 0.85
| | | | |--- feature_0 <= 0.89
| | | | | |--- value: [0.80]
| | | | |--- feature_0 > 0.89
| | | | | |--- feature_0 <= 0.91
| | | | | | |--- feature_0 <= 0.90
| | | | | | | |--- value: [1.13]
| | | | | | |--- feature_0 > 0.90
| | | | | | | |--- value: [1.37]
| | | | | |--- feature_0 > 0.91
| | | | | | |--- value: [1.01]
| | |--- feature_0 > 0.91
| | | |--- feature_0 <= 0.94
| | | | |--- feature_0 <= 0.92
| | | | | |--- value: [1.48]
| | | | |--- feature_0 > 0.92
| | | | | |--- value: [1.39]
| | | |--- feature_0 > 0.94
| | | | |--- value: [1.14]

Wygląda na to, że domyślne drzewo regresyjne stworzyło tak dużo węzłów, że model jest mocno przeuczony. Aby temu zapobiec, ograniczymy głębokość drzewa, czyli maksymalną liczbę węzłów od korzenia do liścia włącznie.
dt_reg2 = DecisionTreeRegressor(max_depth = 3)
dt_reg2.fit(x_train, y_train)
preds_dt2 = dt_reg2.predict(x_valid)
wyniki7 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds4 - y_valid)),
np.sum(np.square(np.reshape(preds_dt2, (25,1)) - y_valid))
],
'R2': [metrics.r2_score(y_valid, preds4),
metrics.r2_score(y_valid, preds_dt2)
],
'MAE': [metrics.mean_absolute_error(y_valid, preds4),
metrics.mean_absolute_error(y_valid, preds_dt2)]},
index=['square_reg', 'dt_reg']).style.background_gradient(cmap='Blues')
wyniki7
| RSS | R2 | MAE | |
|---|---|---|---|
| square_reg | 0.710297 | 0.818960 | 0.131138 |
| dt_reg | 0.574310 | 0.853621 | 0.126859 |
Ograniczenie głębokości drzewa pomogło i model jest teraz skuteczniejszy niż regresja kwadratowa. Przykładowe hiperparametry, które można regulować/optymalizować to:
criterion - kryterium wyboru podziału węzła,
min_samples_split - minimalna liczba wartości do podzielenia węzła,
min_samples_leaf - minimalna liczba wartości w liściu drzewa,
max_depth - maksymalna głębokość drzewa.
print(export_text(dt_reg2))
fig = plt.figure(figsize=(25,20))
_ = plot_tree(dt_reg2, filled=True)
|--- feature_0 <= 0.56
| |--- feature_0 <= -0.74
| | |--- feature_0 <= -0.79
| | | |--- value: [0.45]
| | |--- feature_0 > -0.79
| | | |--- value: [0.29]
| |--- feature_0 > -0.74
| | |--- feature_0 <= 0.38
| | | |--- value: [0.03]
| | |--- feature_0 > 0.38
| | | |--- value: [0.47]
|--- feature_0 > 0.56
| |--- feature_0 <= 0.80
| | |--- feature_0 <= 0.62
| | | |--- value: [0.57]
| | |--- feature_0 > 0.62
| | | |--- value: [0.84]
| |--- feature_0 > 0.80
| | |--- feature_0 <= 0.91
| | | |--- value: [1.12]
| | |--- feature_0 > 0.91
| | | |--- value: [1.34]
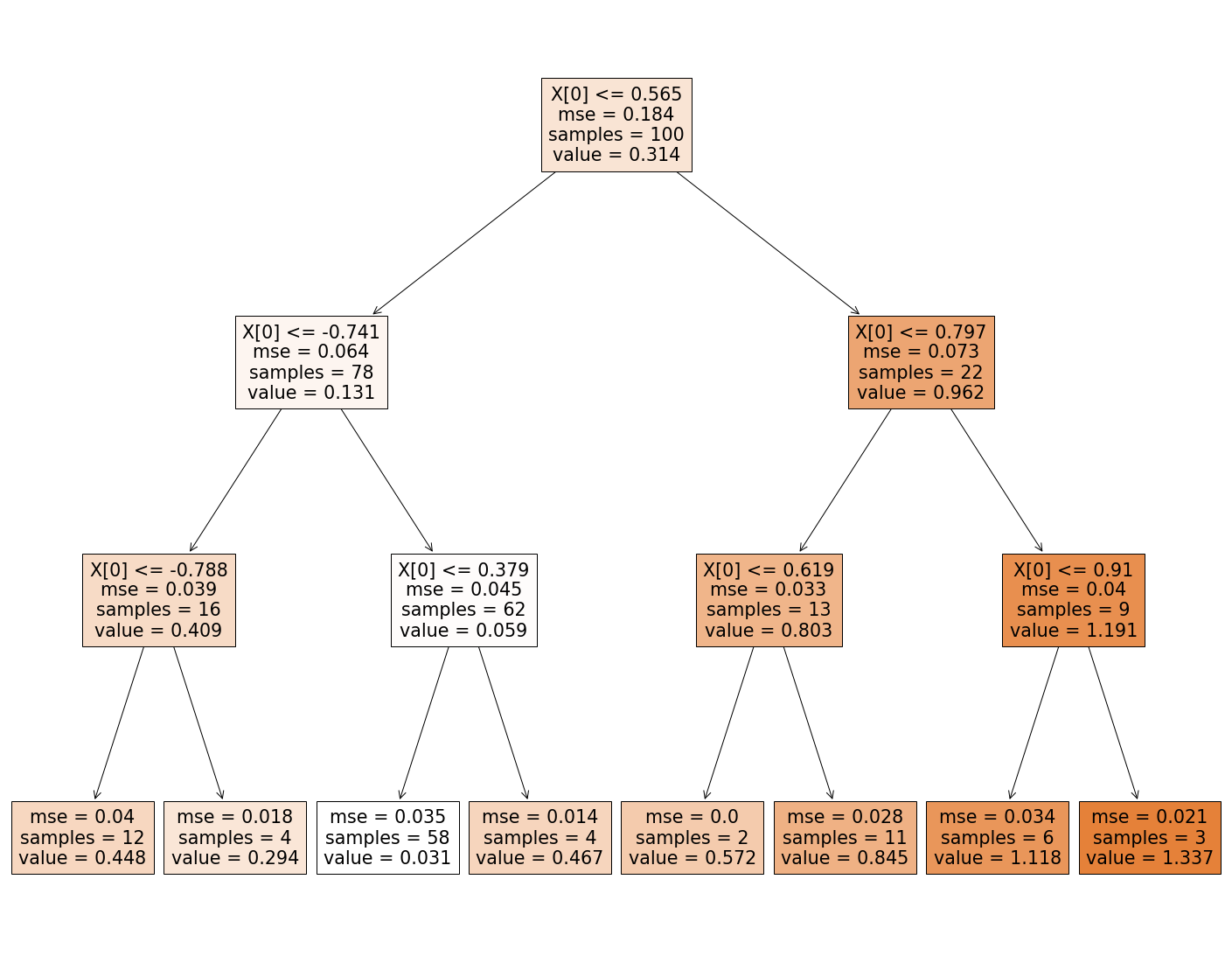
Na koniec tej części, warto wspomnieć o paru istotnych informacjach dotyczących drzew decyzyjnych.
Drzewa decyzyjne nie wymagają wcześniejszej standaryzacji danych - co więcej, ewentualna standaryzacja nie wpływa na wyniki oraz predykcję.
Drzewa decyzyjne mają skłonność do przeuczania się.
Pracując z drzewami, należy uważać przy detekcji outlierów - jeśli wykluczymy outliery ze zbioru treningowego, a analogiczne znajdą się w zbiorze testowym lub walidacyjnym, drzewo może takich wartości nie obsłużyć i zwrócić mocno niepoprawne predykcje.
W praktyce, drzewa decyzyjne wykorzystuje się głównie jako algorytm pomocniczy w algorytmach ensemble, takich jak na przykład Random Forest, LightGBM czy XGBoost.
Random forest¶
Jak wspomniano wyżej, lasy losowe, bardziej znane pod nazwą random forest, są algorytmem ensemble, czyli wykorzystującym wiele modeli (algorytmów) jednocześnie. W przypadku lasów są to, jak sama nazwa wskazuje, drzewa decyzyjne. Konkretnie, ten algorytm tworzy \(n\) drzew decyzyjnych, a następnie (w regresji) dla ustalonego rekordu ze zbioru testowego/walidacyjnego, zwraca średnią predykcję z tych drzew jako swoją predykcję dla owego rekordu.
Konstrukcja
Oczywiście, aby tworzenie wielu drzew decyzyjnych miało w ogóle sens, nie mogą być one identyczne. Taki efekt uzyskuje się łącząc dwie metody związane z losowaniem. Pierwszą z nich jest bagging, czyli bootstrap aggregating. Ten algorytm polega na tworzeniu nowego zbioru danych przez losowanie rekordów ze zbioru treningowego ze zwracaniem. Dzięki temu, każde drzewo z dużym prawdopodobieństwem będzie wytrenowane na innym zbiorze danych. Drugim elementem baggingu jest agregacja, czyli opisane wcześniej uśrednienie predykcji modeli pomocniczych.
Poza losowaniem danych treningowych dla każdego podmodelu, same drzewa również zawierają w sobie element losowości. Mianowicie, optymalny warunek dla każdego węzła jest determinowany jedynie na podstawie losowego podzbioru zmiennych objaśniających. Taka konstrukcja lasów redukuje skłonność podedynczego drzewa do przeuczania się. Nie ma ona jednak wpływu na problem drzew decyzyjnych z outlierami, a także nie zmienia tego, że standaryzacja nie zmienia wyników algorytmu.
Hiperparametry
Przykładowe hiperparametry lasów losowych:
criterion - kryterium wyboru podziału węzła - jak w drzewach decyzyjnych,
min_samples_split - minimalna liczba wartości do podzielenia węzła - jak w drzewach decyzyjnych,
min_samples_leaf - minimalna liczba wartości w liściu drzewa - jak w drzewach decyzyjnych,
max_depth - maksymalna głębokość drzewa - jak w drzewach decyzyjnych,
max_features - liczba cech do rozpatrzenia w wyborze podziału każdego węzła,
max_samples - liczba rekordów każdego losowego podzbioru do treningu drzew,
n_estimators - liczba drzew w lesie.
Teraz zamodelujemy nasze dane lasem losowym.
rf_reg = RandomForestRegressor()
rf_reg.fit(x_train,np.reshape(y_train, (100,)))
rf_preds = rf_reg.predict(x_valid)
wyniki8 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds4 - y_valid)),
np.sum(np.square(np.reshape(preds_dt2, (25,1)) - y_valid)),
np.sum(np.square(np.reshape(rf_preds, (25,1)) - y_valid)),
],
'R2': [metrics.r2_score(y_valid, preds4),
metrics.r2_score(y_valid, preds_dt2),
metrics.r2_score(y_valid, rf_preds),
],
'MAE': [metrics.mean_absolute_error(y_valid, preds4),
metrics.mean_absolute_error(y_valid, preds_dt2),
metrics.mean_absolute_error(y_valid, rf_preds),
]},
index=['square_reg', 'dt_reg', 'rf_reg']).style.background_gradient(cmap='Blues')
wyniki8
| RSS | R2 | MAE | |
|---|---|---|---|
| square_reg | 0.710297 | 0.818960 | 0.131138 |
| dt_reg | 0.574310 | 0.853621 | 0.126859 |
| rf_reg | 0.982969 | 0.749462 | 0.150648 |
Domyślne wyniki znowu są słabe, więc znowu spróbujemy dostosować hiperparametr max_depth.
rf_reg2 = RandomForestRegressor(max_depth = 3)
rf_reg2.fit(x_train,np.reshape(y_train, (100,)))
rf_preds2 = rf_reg2.predict(x_valid)
wyniki9 = pd.DataFrame(data = {'RSS':[np.sum(np.square(preds4 - y_valid)),
np.sum(np.square(np.reshape(preds_dt2, (25,1)) - y_valid)),
np.sum(np.square(np.reshape(rf_preds2, (25,1)) - y_valid)),
],
'R2': [metrics.r2_score(y_valid, preds4),
metrics.r2_score(y_valid, preds_dt2),
metrics.r2_score(y_valid, rf_preds2),
],
'MAE': [metrics.mean_absolute_error(y_valid, preds4),
metrics.mean_absolute_error(y_valid, preds_dt2),
metrics.mean_absolute_error(y_valid, rf_preds2),
]},
index=['square_reg', 'dt_reg', 'rf_reg']).style.background_gradient(cmap='Blues')
wyniki9
| RSS | R2 | MAE | |
|---|---|---|---|
| square_reg | 0.710297 | 0.818960 | 0.131138 |
| dt_reg | 0.574310 | 0.853621 | 0.126859 |
| rf_reg | 0.490039 | 0.875099 | 0.111054 |
W efekcie uzyskaliśmy najlepszy z trzech modeli.
Inne modele¶
XGBoost¶
XGBoost również należy do grupy algorytmów ensemble i także bazuje na drzewach decyzyjnych, jednak działa nieco inaczej niż random forest. Mianowicie, XGBoost na początek generuje wyjściową predykcję (w przypadku regresji jest to z reguły średnia wartość zmiennej objaśnianej z całego zbioru treningowego), następnie tworzy drzewo decyzyjne na resztach z tej predykcji, wyliczając tym samym oczekiwany błąd, zmniejsza ów błąd mnożąc go przez liczbę z przedziału \((0,1)\), i ostatecznie dodaje pomniejszony błąd do predykcji wyjściowej, tworząc nową predykcję. Jest to proces iteracyjny, potwarzany \(n\) razy. Opisany tu algorytm nosi nazwę Gradient Boosting, zaś XGBoost jest jego implementacją, która wyróżnia się przede wszystkim metodą konstruowania kolejnych drzew decyzyjnych - poziom po poziomie.
LightGBM¶
LightGBM jest bardzo podobnym algorytmem do XGBoost, czyli również korzysta z Gradient Boostingu. Główna różnica między nimi to wymieniony wyżej sposób konstruowania pomocniczych drzew decyzyjnych - tutaj każdy nowy węzeł jest zawsze tym najlepszym w danym momencie, niezależnie od poziomu głębokości drzewa tego węzła. Poza tym te algorytmy nieco inaczej obsługują zmienne kategoryczne. LightGBM jest też dużo lżejszym algorytmem, co zresztą narzuca sama nazwa - jest szybszy w działaniu i wymaga mniej pamięci, a mimo to daje bardzo zbliżone rezultaty - w dokumentacji można nawet przeczytać, że lepsze :)
Sieci neuronowe¶
Sieci neuronowe to funkcje ideowo oparte o konstrukcję zwierzęcego mózgu. Składają się one z warstw neuronów, które pobierają liczby, transformują je i przekazują do kolejnych warstw. Pierwszą warstwę nazywa się wejściową, ostatnią wyjściową, zaś wszystkie warstwy pomiędzy nazywa się ukrytymi. Z reguły każdy neuron z warstwy \(k\) jest połączony z każdym neuronem z warstwy \(k+1\).
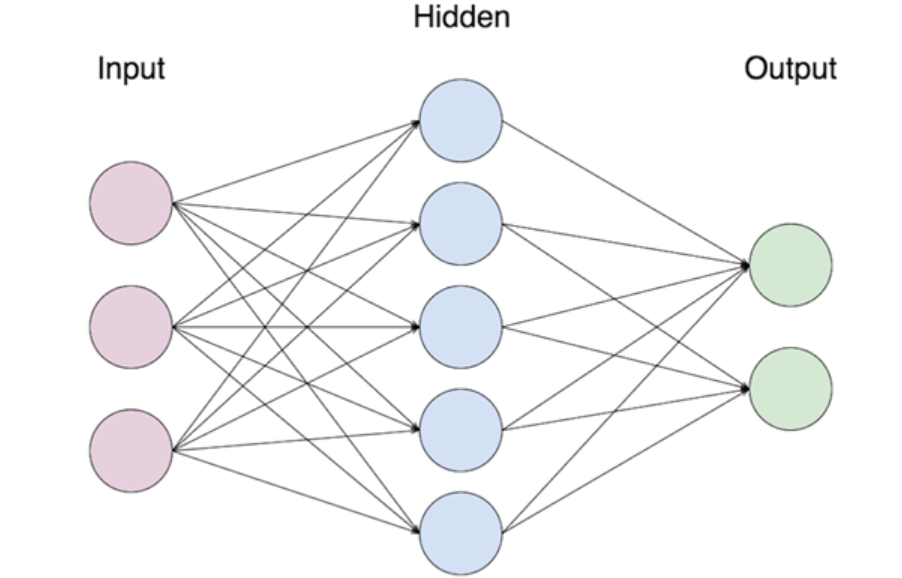
Formalnie, sieć neuronową można zdefiniować jako naprzemienne złożenie \(n\) funkcji afinicznych i \(n\) funkcji zwanych aktywacyjnymi, z których każda, poza ostatnią, nie może być wielomianem. Wzór ogólny sieci, która ma \(n-1\) warstw ukrytych, dany jest jako
gdzie \(W_I\) to funkcje afiniczne, czyli postaci \(W_i(x)=A_i(x)+B_i\), gdzie \(A_i\) to funkcja liniowa, a \(B_i\) jest wektorem, zaś \(\sigma_i\) to funkcje aktywacyjne. Wartości funkcji afinicznych nazywa się wagami i to one są dopasowywane w procesie uczenia sieci. W regresji ostatnia funkcja aktywacyjna dana jest wzorem \(\sigma_n(x)=x\). Fakt, że w warstwach ukrytych funkcje aktywacyjne nie są wielomianami, nadaje sieciom nieliniowość, która jest motorem napędowym ich skuteczności. W szczególności, taka postać tych funkcji sprawia, że sieci neuronowe mają tę samą własność co wielomiany w twierdzeniu Weierstrassa - są gęste w zbiorze funkcji ciągłych. Link do twierdzenia: https://en.wikipedia.org/wiki/Universal_approximation_theorem.
Sieci neuronowe uczą się z wykorzystaniem algorytmów minimalizacji straty, takich jak spadek gradientu, oraz przy użyciu algorytmu propagacji wstecznej - strata jest minimalizowana z warstwy do warstwy, rozpoczynając od ostatniej, czyli wyjściowej.
Taka sieć jest jednak dopiero podstawą dla bardziej zaawansowanych i częściej stosowanych sieci. Do takich zalicza się sieci konwolucyjne (CNN), rekurencyjne (RNN) czy grafowe (GNN). Regresja jest tylko jednym z wielu zastosowań sieci. Warto również wspomnieć, że z reguły sieci neuronowe uczą się tym lepiej, im więcej danych mają do dyspozycji.
Bibliografia¶
The Elements of Statistical Learning Trevor Hastie, Robert Tibshirani, Jerome Friedman. Second Edition.